常见问题和解决方法
版本:1.5.0
最后更新:2026/07/03
常见问题和解决方法控制中心如何更改控制中心端口号?在控制中心运行时修改了IP地址、防火墙状态,例如启动、停止或重启了防火墙,导致控制中心不能访问为控制中心docker的bridge指定自定义网段控制中心同时作为源主机时,控制中心可能无法访问或连接代理控制中心启动失败,手动启动时报错“container name is already in use”在CentOS平台控制中心启动时报错 “ERROR:dbus.proxies:Introspect error on :1.7:/org/fedoraproject/FirewallD1: dbus.exceptions.DBusException:”,控制中心仍可正常访问在银河麒麟V10上安装控制中心,容器无法启动,报错信息"docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:318: starting container process caused "permission denied": unknown"控制中心经过一段时间后无法登陆,登录页面一直在加载控制中心登录页面点击登录后白屏,或无法登录检查主机是否满足Easync代理运行条件如何恢复已删除的计划如何删除隐藏的计划计划处于切换准备就绪状态,但切换按钮是灰色,停止按钮也是灰色如何卸载控制中心Easync代理(Agent)如何手动安装Easync Agent如何手动安装Easync Agent(旧版本)如何手动卸载Easync Agent如何手动卸载Easync对象存储代理(OBS Agent)如何更改代理的端口号?安装时安装后计划运行时报错“没有找到适配当前内核xxxx的驱动“并停止Linux源主机运行前检查时报错“源主机上空闲的loop设备不足”但losetup -a输出为空Linux源主机运行前检查时报错“源主机上空闲的loop设备不足”Windows平台代理安装问题排查步骤汇总安装日志显示“Failed to connect to xxx:22”错误,或连通性诊断所有项目都不通过采用推送安装采用拉取安装安装代理后控制中心页面显示主机无法连接、未安装、代理版本未知、未运行等手动安装代理后,连通性诊断没有问题,但计划运行前检查报错无法连接主机(主机证书和控制中心证书不一致)Windows平台,推送安装前需在主机上配置winrmWindows平台,使用非内置administrator的其他管理员账户,无法推送安装Windows平台,源主机安装360安全卫士、火绒、mcAfee等安全杀毒软件可能导致代理安装、升级、计划运行、同步、切换失败Windows平台,关闭360等安全软件后,仍然无法安装代理,且远程推送安装日志没有报错Windows平台,推送安装不成功,安装日志里有多个错误,例如wmic、powershell不可用Windows主机推送安装代理失败,安装日志显示"Authentication (publickey) failed"或"Exception: the specified credentials were rejected by the server"在Windows 2016及以后操作系统上安装Agent时弹出"A digitally signed driver is required"在Windows 2008 R2等源主机上运行winrm quickconfig报出”拒绝访问“错误源主机或目标机状态不正常,如有红色叹号或灰色,无法运行、停止计划、不同步数据、或频繁报错发送文件失败,代理日志中包含重复的sqlite3错误Debian 11需要安装linux-image-$(uname -r)-dbg包es_sys运行报错error while loading shared libraries: libz.so.1: failed to map segment from shared object系统和依赖整机迁移、容灾对生产机业务的影响?迁移后操作系统、应用软件是否需要重新激活?是否支持Intel/AMD/海光CPU之间迁移?迁移后目标机和源主机数据是否完全一致?是否同步全盘大小的数据?在数据复制过程中如何对源、目标两端数据进行一致性对比?是否支持断点续传?是否需要/如何进行二次增量同步?切换前源主机可以关机吗?统计信息中显示的数据压缩率是怎么计算的?数据同步速度太慢或太快?产品对网络带宽、延时要求?产品RPO/RTO指标?源主机为UEFI/BIOS引导,计划运行时可能报错缺少BIOS/UEFI依赖包若目标机为UEFI引导若目标机为BIOS引导 Linux平台为代理手动安装离线依赖包RHEL/CentOS/OracleLinux 6源主机的容灾计划已知限制创建云平台账户、或者运行计划时,出现报错"error context deadline exceeded"、"无法连接云平台"是否支持集群的迁移是否支持迁移共享卷整机迁移、容灾方案按节点授权计数方法怎样将目标机启动到RamOS系统?支持同时运行的计划数量是多少?控制中心虚拟代理机(VA)容灾目标机网络和防火墙控制中心页面上源主机、目标机的连通性诊断开启了iptables的CentOS 6主机重启后控制中心可能无法连接Easync代理Easync liveCD如何设置静态IPEasync WinPE如何设置静态IPWindows容灾目标机添加主机解析记录Easync WinPE添加主机解析记录控制中心或源主机无法连接目标机、无法获取目标机信息SMTX验证云平台账户、创建备份目标时无法列出集群信息、或计划运行时错误,后台日志报告401错误目标网络设置使用基于云平台的网络设置时,例如IP漂移,网卡漂移,无法获取某一个节点的系统信息,但云平台账户设置和代理连通性验证都没问题主备切换源主机和目标机之间的BIOS/UEFI相互转换支持情况通用模式虚拟化模式Windows 2012 R2 EFI启动的源主机,在虚拟代理模式切换后,虚拟机显示grub启动选择界面,选择RHEL/CentOS后无法启动Windows域控(Domain Controller)源主机,AD数据库NTDS、SYSVOL目录安装到了C盘以外的盘符,切换时目标机启动蓝屏数据同步完成但一直没有进入切换准备就绪状态灾备机启动过程中磁盘扫描程序无限滚动报错Deleted invalid filename xxx in directory xxx切换后目标机硬盘使用空间和源主机不一致RHEL/CentOS 6迁移,如果OS没有单独/boot分区,而且目标机系统盘>=2TB,切换后备机可能启动失败,进入grub shellRHEL/CentOS 5从其他虚拟平台迁移到KVM平台,启动后无法进入图形用户界面(X server)RHEL/CentOS 5源主机切换到KVM虚拟化平台上时,虚拟机可能出现无规律的断网RHEL/CentOS 5源主机切换到KVM虚拟化平台上时,虚拟机可能出现"找不到卷组"无法启动RHEL/CentOS 5源主机使用通用模式容灾切换后,如果想把目标机启动到容灾目标机自有OS,需要手动在grub菜单选择RHEL/CentOS/Oracle Linux 6源主机切换到KVM虚拟化平台上时,虚拟机可能出现"No root device found"或"LVM xxx not found"无法启动CentOS主机切换后登陆报密码错误。启动过程有Failed to start Login service错误Linux源主机切换后备机启动,根文件系统/显示为只读文件系统(read only file system)CentOS/RHEL 4 切换后,目标机可能没有网络IPSuSE Linux Enterprise Server (SLES) 11 迁移,目标机系统盘需要为IDE总线通用模式高可用、容灾+高可用计划,切换后备机无法启动虚拟化模式,SMTX目标平台,创建基于IDE的目标机SMTX虚拟化模式,切换后目标机VM没有安装vmtools、数据盘没有盘符、网卡没有设置IP等问题Windows源主机,从深信服sangfor平台迁移到其他平台,切换后VM启动可能蓝屏失败Windows源主机,切换后目标机上的数据库服务没有自动启动切换后,目标机/备机的主机名或密码可能不是源主机的主机名或密码,而是目标机创建时的主机名或密码源主机是CentOS 8 ext3文件系统,切换时报更新启动信息失败,查看日志是fsck错误Windows平台切换如何注入其他硬件驱动?是否支持Windows域控制器(DC)整机迁移容灾?VA模式计划运行时报错准备虚拟化环境失败在切换后的目标机上运行自定义脚本通用模式迁移目标机如何指定其他盘为启动盘?整机容灾整机容灾是否支持主机上运行多种数据库和应用?整机容灾方案支持的容灾类型数据恢复粒度如何?Windows平台上数据同步和制作书签时没有调用某个VSS Writer使用prepare-target进入RamOS后不想回切、恢复数据了,如何去除RamOS系统启动菜单数据库(RDS)MySQL如何启用MySQL binlog设置binlog格式为ROW设置binlog保留时间中文编码字段在实时复制时可能报错打开log-bin-trust-function-creators缓存设置数据缓存工作原理如何在RamOS目标机上增加数据缓存(指定缓存盘)?如何在RamOS目标机上增加数据缓存(指定缓存目录)?事件和日志配置事件邮件通知如何将控制中心日志输出到syslog服务器通用模式迁移获取源和目标端迁移过程完整日志排错时需要收集的信息截图日志代理运行异常时获取更多诊断信息
控制中心
如何更改控制中心端口号?
控制中心默认监听TCP 8443端口。有如下方法更改端口号。
安装时指定端口号
参数 -p指定端口号。详见安装文档
安装后更改端口号
登录控制中心主机,编辑以下配置文件(如果文件不存在请创建),写入端口号,保存退出。
vi /opt/cloudock/easync/cc/data/ccport.conf运行以下命令重新启动控制中心。请等待启动完成,就可用新端口号访问控制中心。
esccmgr restart
在控制中心运行时修改了IP地址、防火墙状态,例如启动、停止或重启了防火墙,导致控制中心不能访问
如果在Easync控制中心运行时修改了IP地址、或启动、停止了防火墙(iptables/firewalld/ufw),就需要执行下面命令重新启动控制中心。否则控制中心无法访问。
esccmgr restart
为控制中心docker的bridge指定自定义网段
控制中心安装时docker创建bridge easyncnet是自动选择的网段。如果和用户自有网段冲突,可以修改easyncnet网段。在控制中心主机上执行如下命令。将172.30.0.0/16替换为期望的网段。
esccmgr stopdocker network rm easyncnetdocker network create --subnet=172.30.0.0/16 --gateway=172.30.0.1 easyncnet
docker0为docker engine自动创建的默认bridge。重启docker服务将自动创建,修改docker0的网段,执行如下步骤:
vi /etc/docker/daemon.json
填写如下内容,指定期望的网段
xxxxxxxxxx{"bip": "172.31.0.1/16"}
保存退出。运行如下命令:
xxxxxxxxxxsystemctl restart dockerip a|grep inet #将看到docker0网段变为期望的网段esccmgr start
控制中心同时作为源主机时,控制中心可能无法访问或连接代理
Note
不支持控制中心同时作为虚拟代理机。虚拟代理机必须为专用VM。
这是由于启动控制中心和agent的安装会添加所需的防火墙规则而可能导致firewalld/ufw和iptables规则互相清除。
RHEL/CentOS系列,运行以下命令:
xxxxxxxxxxsystemctl stop firewalldsystemctl disable firewalldesccmgr restartsystemctl restart easync-agentDebian/Ubuntu系列,运行命令:
xxxxxxxxxxufw disableesccmgr restartsystemctl restart easync-agent
控制中心启动失败,手动启动时报错“container name is already in use”
当手动启动控制中心时,遇到下列错误信息
xesccmgr start... error creating container storage: the container name xxx is already in use by "xxx". You have to remove that container to be able to reuse that name.: that name is already in use
请以root或sudo方式尝试下列步骤,假定容器为podman,如果容器为docker,请相应替换命令。
停止控制中心服务
esccmgr stop查看是否有遗留容器。
podman ps -a如果有遗留容器,运行命令进行删除
podman rm -f xxx查看是否有docker遗留状态
vi /var/lib/containers/storage/overlay-containers/containers.json如果内容不为空,清空内容,保存退出。
重新启动控制中心服务
esccmgr start
在CentOS平台控制中心启动时报错 “ERROR:dbus.proxies:Introspect error on :1.7:/org/fedoraproject/FirewallD1: dbus.exceptions.DBusException:”,控制中心仍可正常访问
当安装或启动控制中心时,遇到下列错误信息
xxxxxxxxxxERROR:dbus.proxies:Introspect error on :1.7:/org/fedoraproject/FirewallD1: dbus.exceptions.DBusException: org.freedesktop.DBus.Error.NoReply: Did not receive a reply. Possible causes include: the remote application did not send a reply, the message bus security policy blocked the reply, the reply timeout expired, or the network connection was broken.
这个异常通常和selinux阻止firewalld自动配置有关。
如果控制中心能正常访问,则可以忽略这个错误。如果控制中心不能正常访问,请依次尝试如下步骤,直到控制中心能正常访问:
重新启动firewalld及控制中心
systemctl stop firewalldsystemctl start firewalldesccmgr restart如果控制中心仍然不能访问,尝试停止firewalld,启动控制中心
systemctl stop firewalldesccmgr restart如果控制中心仍然不能访问,尝试停止selinux,启动控制中心
setenforce 0esccmgr restart
在银河麒麟V10上安装控制中心,容器无法启动,报错信息"docker: Error response from daemon: failed to create shim: OCI runtime create failed: container_linux.go:318: starting container process caused "permission denied": unknown"
请检查主机上是否存在低版本的podman,如果有,请将其删除,再次运行安装。
yum remove podman
控制中心经过一段时间后无法登陆,登录页面一直在加载
请检查磁盘 / 下剩余空间。如果 / 下磁盘空间已满,请清理空间。
df -h
另外,运行如下命令查看容器是否运行正常。如果某个容器的启动时间比别的容器明显要更新,意味着此容器可能崩溃重启或反复重启,可以查看相应容器日志帮助排查。
xxxxxxxxxxdocker psdocker logs <container name>
控制中心登录页面点击登录后白屏,或无法登录
请依次排查:
控制中心主机硬盘剩余空间是否耗尽
df -h是否更改过控制中心的网络,
esccmgr restart重启控制中心如果控制中心部署在公有云或其他带宽受限制网络,确保控制中心到web客户端的带宽 >= 8Mbps,否则可能因为带宽太小无法正常加载页面数据。
查看容器是否运行正常,
docker ps,不应该有容器反复自动重启支持的浏览器为FireFox、Chrome、Edge,如果是其他浏览器请更换。均要求版本号100以上,否则登录界面有浏览器版本过低的提示。
检查主机是否满足Easync代理运行条件
以下命令需要在控制中心主机上运行。
将检查下列条件用来判断是否满足作为Easync主机的条件:
主机是否可连接(失败提示:检查防火墙或安全组端口策略,账户,Windows服务器是否已打开winrm)
用户名密码是否正确
用户需要为root或sudo用户
是否为受支持的操作系统版本
是否为64 bit。只支持64 bit系统
是否存在 / 文件系统
/ 剩余空间是否>= 1GB,安装占用500-800MB
/ 额外剩余或任意卷剩余空间>=2GB,给data spool
是否所需KB已经安装 (Windows)
对CentOS/RHEL/OEL 5是否已安装python
如果检查结果为通过,则输出”通过“;如果未通过,则输出相应的错误信息。请参见下方示例输出。
注意,错误检查是渐进式的。如果有多项错误,则每次检查只会报出遇到的第一项错误条件,修正后请再次进行检查。
检查方法:
检查单台主机
esccmgr check-host --host ip --user root|administrator --passwd password --type linux|windows例如:
esccmgr check-host --host 192.168.6.100 --user root --passwd testpass --type linuxesccmgr check-host --host 192.168.6.101 --user administrator --passwd testpass --type windows批量检查主机
创建一个文本文件作为配置文件,每一行为要检查的一条主机记录,字段之间用空格或制表符隔开。格式为:
主机IP 用户名 密码 类型
例如如下配置文件
xxxxxxxxxxcat conf.txt10.20.50.211 administrator pass1234 windows10.20.50.212 "bj\esadmin" pass1234 windows10.20.50.213 root pass1234 linux10.20.50.214 root pass1234 linux将此配置文件作为参数调用
/opt/cloudock/easync/common/remote-check-hosts.sh conf.txt程序将逐一检查各个主机,并打印检查结果。检查结果将保存在check-result.txt文件中。示例结果如下:
xxxxxxxxxx10.20.50.211 检查结果:通过10.20.50.212 检查结果:无法连接主机。请检查用户名/密码, 在主机上运行命令(winrm quickconfig)允许WinRM远程连接, 并确保安全组或防火墙开放端口TCP 5985/7822/198410.20.50.213 检查结果:通过10.20.50.214 检查结果:已安装
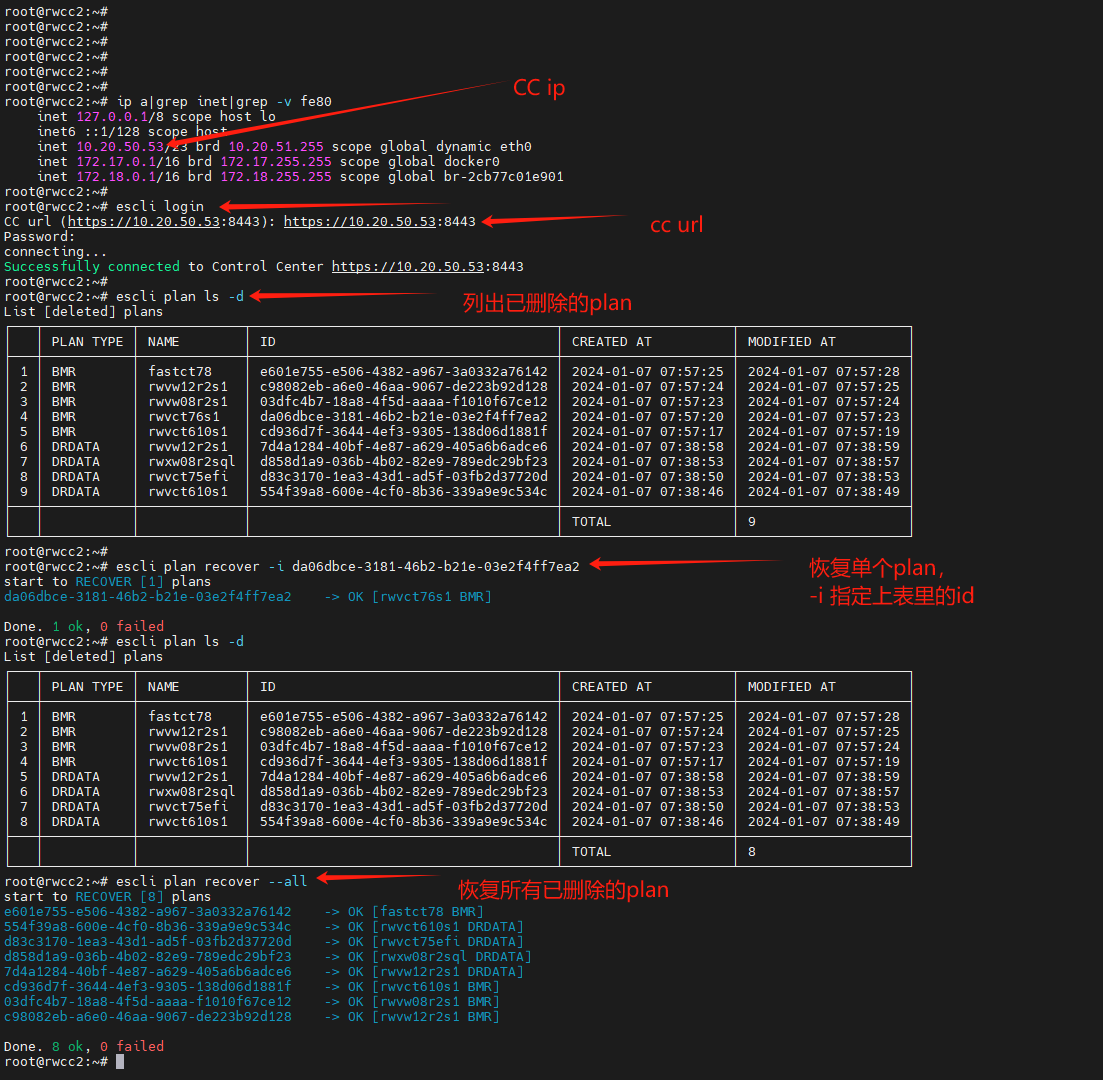
如何恢复已删除的计划
登录控制中心,执行以下命令:
escli login 输入控制中心URL(https://ip:port),然后输入密码
escli plan ls -d 列出所有已删除计划
escli plan recover --all 恢复所有已删除的计划
如果想恢复单个计划,用 -i 参数指定计划ID
escli plan recover -i id 恢复指定id的计划
如何删除隐藏的计划
如果在创建计划时刷新页面,可能造成计划创建不完整,造成主机已经关联计划,但GUI未显示计划。此时可以用命令行删除该计划。
登录控制中心,执行以下命令:
escli login 输入控制中心URL(https://ip:port),然后输入密码
escli plan ls 列出所有计划
定位要删除的计划,复制ID
escli plan delete -i id
例如
escli plan delete -i 4463d223-bb6c-41bf-81ec-ad47e513061f

回到GUI界面,计划已经删除。在源主机列表页面,对应的源主机显示为橙色,代表无计划关联,可以新建计划。
计划处于切换准备就绪状态,但切换按钮是灰色,停止按钮也是灰色
该问题发现在Edge浏览器某些版本。请尝试F5刷新页面,如果还是有问题请更换火狐(firefox)、Chrome再次尝试。
如何卸载控制中心
强烈建议控制中心安装在一台专用机器上,当不再需要控制中心时,删掉机器即可。
如果需要手动卸载清除Easync控制中心及相关文件,请以**root**用户执行以下步骤
运行命令停止控制中心服务
esccmgr stop删除安装目录
rm -rf /opt/cloudock删除Easync docker镜像
xxxxxxxxxxdocker rmi cd78/escc-j11p3:6068 \cd78/esmkramiso:latest \postgres:14 \influxdb:2.1.1 \mongo:4.0 \nginx:stable \node:15-alpine \redis:6注意:这些镜像是Easync在安装控制中心部署的依赖镜像,删除前请确保没有其他应用或服务在使用这些镜像。
可选的,如果docker或podman不再使用,请运行以下命令可以卸载,或查询相应文档。
CentOS
yum remove -y docker-ce docker-ce-cliyum remove -y podmanUbuntu
apt remove -y docker-ce docker-ce-cli
删除以下文件
rm -f /usr/bin/esccmgrrm -f /root/.escc.conf
Easync代理(Agent)
如何手动安装Easync Agent
注意:应首选使用控制中心的”推送安装“和”拉取安装“方式进行远程安装。只有在上述两种方式都不可用的情况下,才考虑手动安装。
登录控制中心进入 /opt/cloudock/easync/cc/download 目录,ll easync-agent-*,列出类似如下
xxxxxxxxxxeasync-agent-1.5.0-10857.aarch64.deb #debian系列, arm64easync-agent-1.5.0-10857.el.aarch64.rpm #rhel系列 版本>=6, arm64easync-agent-1.5.0-10857.el.x86_64.rpm #rhel系列 版本>=6, x64easync-agent-1.5.0.10857.windows.x86_64.exe #windows, x64easync-agent-1.5.0-10857.x86_64.deb #debian系列, x64easync-agent-base-1.5.0-10857.aarch64.deb #debian系列, arm64easync-agent-base-1.5.0-10857.el4.x86_64.rpm #rhel系列 版本=4, x64easync-agent-base-1.5.0-10857.el5.x86_64.rpm #rhel系列 版本=5, x64easync-agent-base-1.5.0-10857.el.aarch64.rpm #rhel系列 版本>=6, arm64easync-agent-base-1.5.0-10857.el.x86_64.rpm #rhel系列 版本>=6, x64easync-agent-base-1.5.0-10857.ub.x86_64.deb #Ubuntu 14.04easync-agent-base-1.5.0-10857.x86_64.deb #debian系列, x64
Agent离线安装包按平台步骤:
安装代理
Linux
在控制中心主机上,运行如下命令,生成适用源、目标主机的agent离线安装包。
xxxxxxxxxxcd /opt/cloudock/easync/cc/download./make-agent-offline-install-pkg.sh <agent-file>agent-file 指适用要安装代理主机OS的上述 rpm/deb:
对源主机,请选择
easync-agent-base-文件;也可以用
easync-agent-文件,其文件大小要稍大。对容灾目标机、虚拟代理机,请选择
easync-agent-文件。
命令将生成一个.tgz文件,包含指定的rpm/deb,以及代理依赖包、通信证书等文件。

将上述 .tgz离线安装包复制到要安装代理的机器,解压,并进行安装。
xxxxxxxxxxtar xzf easync-agent-base-1.5.0-10857.el.x86_64.rpm-offline.tgzcd es-agent-install/chmod +x offline-install-agent.sh./offline-install-agent.sh如果没有错误,程序最终将显示
done。
Windows
将
easync-agent-<version>.windows.x86_64.exe复制到主机,双击进行安装。将控制中心下面两个证书文件
/opt/cloudock/easync/cc/data/easync-g.crt
/opt/cloudock/easync/cc/data/easync-g.key
复制到主机的C:\Program Files\Cloudock\Easync\agent\data\ 目录。重新启动Easync agent服务(服务mmc页面,或任务管理器->服务标签页)
添加主机
在控制中心管理页面->主机列表->添加源主机,选择 推送安装,输入IP,不勾选“自动安装”、“强制安装”两个复选框,点击保存。点击右上角 刷新主机信息,将显示代理版本号和绿色运行状态。
如何手动安装Easync Agent(旧版本)
注意:应首选使用控制中心的”推送安装“和”拉取安装“方式进行远程安装。只有在上述两种方式都不可用的情况下,才考虑手动安装。
手动安装步骤:
在控制中心主机上,将如下位置的agent安装包及依赖包复制到源主机的任意同一目录下。
agent安装包:
请在控制中心主机如下路径,根据源主机平台选择安装包。对于Linux平台,请选择
easync-agent-base-安装包。注意如果是针对容灾目标机、虚拟代理机安装代理,请选择
easync-agent-安装包。xxxxxxxxxx/opt/cloudock/easync/cc/download/easync-agent-<version>.windows.x86_64.exe/opt/cloudock/easync/cc/download/easync-agent-base-<version>.el.aarch64.rpm/opt/cloudock/easync/cc/download/easync-agent-base-<version>.el.x86_64.rpm/opt/cloudock/easync/cc/download/easync-agent-base-<version>.el4.x86_64.rpm/opt/cloudock/easync/cc/download/easync-agent-base-<version>.el5.x86_64.rpm/opt/cloudock/easync/cc/download/easync-agent-base-<version>.aarch64.deb/opt/cloudock/easync/cc/download/easync-agent-base-<version>.x86_64.deb/opt/cloudock/easync/cc/download/easync-agent-base-<version>.ub.x86_64.deb (for Ubuntu 14.04)agent依赖包:(仅针对Linux平台。Windows平台无需依赖包,注意Windows 7、Server2008/2008 R2如需启用CDP需要KB4474419补丁,可以在平台支持列表页面下载)
/opt/cloudock/easync/cc/download/agent-needs.tgz/opt/cloudock/easync/cc/download/grub2-needs.tgz/opt/cloudock/easync/cc/download/es_install_tools_offline.sh
安装agent依赖包,再安装agent
Windows
双击安装文件
easync-agent-<version>.windows.x86_64.exe直接安装CentOS/RHEL/Oracle Linux
./es_install_tools_offline.sh -crpm -Uvh easync-agent-<version>.el.<arc>.rpmUbuntu/Debian
./es_install_tools_offline.sh -cdpkg -i easync-agent-<version>.<arc>.deb
复制控制中心的证书到主机
将控制中心下面两个证书文件
/opt/cloudock/easync/cc/data/easync-g.crt/opt/cloudock/easync/cc/data/easync-g.key复制到主机的agent安装目录子目录
/opt/cloudock/easync/agent/data/(Linux)C:\Program Files\Cloudock\Easync\agent\data\(Windows)重新启动Easync agent服务
Windows
请在服务页面重启Easync Agent服务
Linux
/etc/init.d/easync-agent restart
在控制中心管理页面->主机列表->添加源主机,选择 推送安装,输入IP,不勾选“自动安装”、“强制安装”两个复选框,点击保存。点击右上角 刷新主机信息,将显示代理版本号和绿色运行状态。
如何手动卸载Easync Agent
登录Easync Agent主机,执行下面操作
Windows
进入添加删除程序,卸载Cloudock Easync Agent
删除
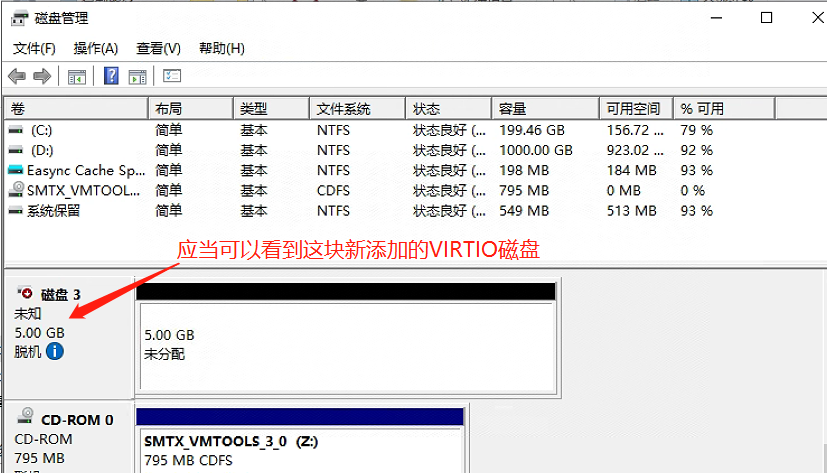
C:\Program Files\Cloudock目录如果报错目录无法删除,请打开磁盘管理,手动卸载Spool磁盘,再删除目录即可。
CentOS/RHEL/Oracle Linux
运行以下命令:
rpm -e easync-agentrm -rf /opt/cloudockUbuntu/Debian
运行以下命令:
dpkg -P easync-agentrm -rf /opt/cloudock
如何手动卸载Easync对象存储代理(OBS Agent)
登录Easync OBS Agent主机,执行下面操作
Windows
运行 C:\Program Files\Cloudock\Easync\obsagent\bin\uninstall.bat
删除
C:\Program Files\Cloudock\Easync\obsagent目录
Linux
运行以下命令:
sudo /opt/cloudock/easync/obsagent/bin/uninstall.shsudo
rm -rf /opt/cloudock/easync/obsagent
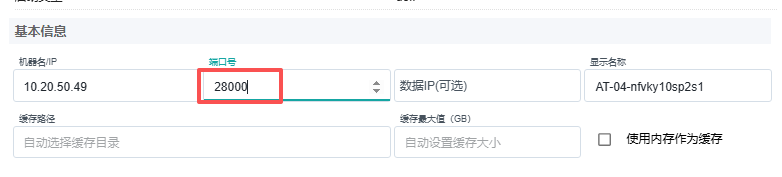
如何更改代理的端口号?
安装时
在主机列表页点击添加源主机,选择推送安装。在端口号字段点击修改,填入端口号,填写其他信息,点击保存。
代理将运行在指定端口号。
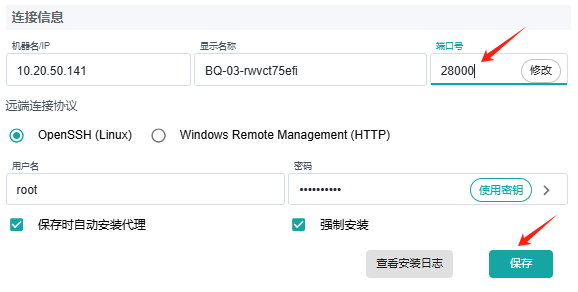
安装后
如果代理已经安装,可以按以下步骤更改端口。当然,也可以先卸载代理,然后使用上面的新安装方法。
登录安装了代理的主机,编辑以下配置文件(如果文件不存在请创建),修改端口号,保存退出。
Linux平台:vi /opt/cloudock/easync/agent/data/es-cfg.json或Windows平台:记事本打开C:\Program Files\Cloudock\Easync\agent\data\es-cfg.json以下示例内容将端口号修改为
28000xxxxxxxxxx{"role": "engine","UseBlockSync": true,"ExcludeCacheData": false,"port": 28000}重启代理服务。
Linux平台:/etc/init.d/easync-agent restartWindows平台:在任务管理器服务页面或服务控制面板重启EasyncAgentService修改计划里的主机端口,如果已经创建计划,保存。
在控制中心管理页面主机列表页,修改该主机右侧属性的端口为新端口,取消“保存时自动安装代理”,保存。
计划运行时报错“没有找到适配当前内核xxxx的驱动“并停止
Note
内核适配指的是为当前内核编写CDP驱动。一般需要1天到1星期。最新6.x内核或非常老的内核可能需要更长时间。个别内核可能无法支持(一般由于该内核为非稳定版本、合并了更新或更旧的内核代码导致前后无法兼容等),这种情况下,用户可以升级内核到支持的版本。
对于Ubuntu、Debian、麒麟桌面版、统信桌面版、统信服务器版d系列,需要针对内核逐个适配。
对麒麟服务器、统信服务器a、e系列、openEuler等平台,一般建议首先尝试Easync自带驱动是否兼容当前内核。
找到一台测试机,从源机克隆或模版分发,安装代理,然后:
cd /opt/cloudock/easync/agent/bin/./try-esvf.sh如果运行结果输出类似如下,则进行下一步,否则不用往下做了。
xxxxxxxxxxloaded esv modules:esvolsnap 49152 0esvf 53248 0使用此测试机创建任意迁移、容灾计划,点击运行。只要数据正常同步,源主机也能正常工作,执行常规ls、vi写文件、df等命令,即可停止并删除计划。
后续可使用生产机创建正常迁移、容灾计划。
如果没有输出或报错,请运行命令
xxxxxxxxxxuname -rcd /opt/cloudock/easync/agent/bin/ls -lh esvf*.ko将截图发送给技术支持人员,将手动确认是否可能存在兼容驱动。
如果当前驱动无法兼容内核,则需要针对当前内核编译驱动。
操作系统 用户提供信息和文件 麒麟桌面版、统信桌面版、统信服务器版a/e/d系列 1. uname -a
2.linux-headers-<当前kernel版本>.deb其他发行版 1. uname -a
2. 一般有公开repo可以找到内核开发包,如果不公开,则需客户相应提供
Linux源主机运行前检查时报错“源主机上空闲的loop设备不足”但losetup -a输出为空
lsmod |grep loop输出为空find /lib/modules/$(uname -r) -type f -name loop*应当列出loop.ko文件depmodmodprobe looplsmod|grep loop应该有输出/etc/init.d/easync-agent restart,然后运行计划。
Linux源主机运行前检查时报错“源主机上空闲的loop设备不足”
如果计划在运行,请在控制中心上停止计划
登录源主机,切换到root用户
运行命令
/etc/init.d/easync-agent stoplosetup -a|grep "easync/agent/data/logspool/spool.dat\|dataspool/spool.dat"将输出的每一行的
spool.dat文件删掉,例如rm -f /opt/cloudock/easync/agent/data/logspool/spool.datrm -f /data/dataspool/spool.dat运行命令
lsblk|grep loop将空闲的
loop设备逐一detach,例如losetup -d /dev/loop0losetup -d /dev/loop5重启代理,然后重新运行计划
/etc/init.d/easync-agent restart
Windows平台代理安装问题排查步骤汇总
以下排查步骤请从上到下逐一进行。
安装日志显示“Failed to connect to xxx:22”错误,或连通性诊断所有项目都不通过
请在控制中心主机上运行如下命令。注意:是控制中心主机,不是你的工作机、桌面机。
请自上而下依次执行,通过检查了,再执行下一条;没有通过,就执行对应的操作:
xxxxxxxxxxping xxxdocker exec -it easync-cc-nethub ping xxxdocker exec -it easync-cc-nethub ssh -v -p 22/5985 xxx #Linux:22, Windows:5985
有的主机设置了不响应ping,那么换一个响应ping的IP尝试。
如果第一条ping不通,请检查主机是否在线、连通性;
如果第二条命令ping不通,可能是容器网络出现问题,请运行 esccmgr restart,再次尝试;
如果第三条命了输出不包含connection established,则是对应端口不能到达,请检查网络中的防火墙等设置。
如果第三条命令通过了,请再次远程安装代理。
采用推送安装
1.5.0-11730版本后,Windows 7、2008、2008 R2需要一个Windows补丁,CDP驱动才能工作,否则只能进行一次性数据同步。请查看系统平台支持列表下载对应补丁包。
Windows主机上、或CC到Windows主机之间,如果有第三方防火墙,则第三方防火墙需要放开源主机
TCP 5985/7822/1984端口。如果没有第三方防火墙,无需操作。
Windows主机上需要运行
winrm quickconfig /q。如果报错请运行powershell Enable-PSRemoting -SkipNetworkProfileCheck, 没有报错即可。Windows系统环境变量
PATH里,如果系统默认的路径被删除了,将导致常用命令如wmic,PowerShell 等无法运行,导致代理无法安装。解决办法:
将下方默认路径添加到系统环境变量 PATH。对于Windows 2016及以后,需要将下方路径按 ; 分割,每行一条添加。
%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;重启 WinRM, WMI 服务。
以下是命令行提示命令。也可以在服务面板找到对应服务进行重启。
xxxxxxxxxxnet stop winrm & net start winrmnet stop "Windows Management Instrumentation" & net start "Windows Management Instrumentation"如果安装有360、火绒等网安软件,会拦截远程推送安装代理。
解决办法:
退出网安软件,再次推送安装。注意360主动防御需要在二级设置里关闭,再退出360,否则主动防御依然在运行。或者
采用拉取安装。
采用拉取安装
1.5.0-11730版本后,Windows 7、2008、2008 R2需要一个Windows补丁,CDP驱动才能工作,否则只能进行一次性数据同步。请查看系统平台支持列表下载对应补丁包。
Windows主机上、或CC到Windows主机之间,如果有第三方防火墙,则第三方防火墙需要放开源主机
TCP 1984端口、和控制中心TCP 8443端口。如果没有第三方防火墙,无需操作。
Windows主机需要访问控制中心
IP:8443端口。尝试在主机上使用浏览器下载https://控制中心IP:8443/server-api/download/prepare-agent.exe来检查条件。如果不能访问请相应排查。
安装代理后控制中心页面显示主机无法连接、未安装、代理版本未知、未运行等
检查代理程序是否成功安装
下列路径应当有程序文件
C:\Program Files\Cloudock\Easync\agent\bin,或/opt/cloudock/easync/agent/bin/,如果路径不存在、为空或只有很少文件,则安装未成功。尝试按上方步骤重新安装。检查代理是否运行
对于Windows平台,在任务管理器-服务页,或服务管理控制台,检查
EasyncAgentService是否运行,es_agent.exe进程是否存在。如果服务未运行,请启动服务。
对于Linux平台,
ps -ef|grep es_agent应有显示。如果服务未运行,
/etc/init.d/easync-agent restart重启服务。
如果服务启动失败:
请打开命令行窗口,运行命令
Windows
xxxxxxxxxxcd "C:\Program Files\Cloudock\Easync\agent\bin"es_agent.exeLinux
xxxxxxxxxxcd /opt/cloudock/easync/agent/bin/./es_agent
查看是否有报错
如果无报错,窗口最后应显示
Start listening on port 1984;如果有报错,请相应排查,将报错截图发给技术支持人员。
命令行卡住,不报错,但是也不返回,代理无法完全启动。
ps -ef查看是否有进程卡住。遇到过sles由于es_sys调用zypper search而zypper repo不存在导致调用卡住,无法返回。解决方法是修复zypper repo(zypper se命令能顺利输出),或者升级至1.5.0-12261之后版本。
Note
故障排查完毕后,如果是这个方式启动的进程,请杀掉当前进程,启动
Easync Agent服务。非服务方式运行的进程有可能会导致后续迁移错误。如果代理进程在运行,检查端口是否监听
运行以下命令:
Windows:
netstat -an|find "1984"或netstat -an|findstr "1984"Windows 2019、10 或以后,运行ssh -v -p 1984 127.0.0.1来确保端口监听正常。更老的版本可以使用putty、telnet 等工具。Linux:
ss -antlp|grep 1984或ss -antlp|grep 1984ssh -v -p 1984 127.0.0.1来确保端口监听正常。
如果代理程序未监听,请检查上一步代理进程运行,排查是否端口冲突等错误。
如果代理已经监听
登录控制中心主机,运行命令
xxxxxxxxxxssh -v -p 1984 <主机IP>docker exec -it easync-cc-nethub ssh -v -p 1984 <主机IP>两条命令输出都应包含
connection established。如果第一条命令输出包含,第二条不包含,说明控制中心容器网络异常,这可能是容器运行中更改了IP地址、更改了防火墙状态,运行
esccmgr restart后再试。如果两条命令输出都显示不包含
connection established,请排查主机防火墙、安全组、CC到主机之间的中间防火墙等。
排除安全软件、杀毒软件的拦截。出现过深信服EDR拦截访问,即使退出程序(实际后台杀毒模块不会退出)也无法访问1984/5985等端口,只能将其卸载,立刻解决问题。
如果是手动安装(不是推送、拉取安装)的代理,请确保控制中心证书已经复制到主机,并已重启代理服务。请查阅手动安装代理部分。
以上问题都排除后,在控制中心页面上选择主机,点击【刷新主机信息】,等待沙漏图标结束,应当显示代理版本、运行状态信息。
手动安装代理后,连通性诊断没有问题,但计划运行前检查报错无法连接主机(主机证书和控制中心证书不一致)
首先请尝试连通性诊断。
如果连通性诊断没问题,但运行前检查仍然报错无法连接主机,请确认主机上的代理是否手动安装,请控制中心证书复制到主机上,重启主机代理。证书路径请参见手动安装代理部分。
Windows平台,推送安装前需在主机上配置winrm
登录主机,运行命令winrm quickconfig /q。如果报错,请运行powershell Enable-PSRemoting -SkipNetworkProfileCheck,没有报错即可。
Windows平台,使用非内置administrator的其他管理员账户,无法推送安装
对于Windows 10/2016及以后源主机,添加源主机时建议使用内置administrator账户。如果使用其他账户,必须是本地管理员组的管理员账户。
如果非内置administrator的管理员账户无法推送安装,报错无法连接,请检查和修改以下注册表项。LocalAccountTokenFilterPolicy
请参见链接进行配置。
Windows平台,源主机安装360安全卫士、火绒、mcAfee等安全杀毒软件可能导致代理安装、升级、计划运行、同步、切换失败
360、火绒等安全软件可能导致代理远程安装失败。请关闭这些软件后再试;或者用拉取安装方式,注意允许这些安全软件的拦截对话框。
如果遇到计划运行长时间不能开始同步数据、切换后目标机不能启动等问题,请检查源主机是否安装360、火绒等安全杀毒软件,请将其完全退出,再次运行计划。注意360的主动防御特性需要在其设置里二级菜单才能关闭,需要先关闭其主动防御,再退出360,否则主动防御依然在运行。
建议将代理安装目录、数据缓存目录添加到上述软件的白名单目录,再运行计划。数据缓存目录默认在剩余空间最大的卷下dataspool/目录,也可以在计划里主机的属性页指定数据缓存路径。
请将下列进程和目录加进白名单:
Windows
进程:
C:\Program Files\Cloudock\Easync\agent\bin\es_agent.exe进程:C:\Program Files\Cloudock\Easync\agent\bin\es_sys.exe目录:C:\Program Files\Cloudock\Easync\目录:c:\Temp\easync_work\目录:数据缓存目录(计划中设定,如果不设定,则自动选择剩余空间最大的卷,创建dataspool子目录,如d:\dataspool)Linux
进程:
/opt/cloudock/easync/agent/bin/es_agent进程:/opt/cloudock/easync/agent/bin/es_sys目录:/opt/cloudock/easync/目录:数据缓存目录(计划中设定,如果不设定,则自动选择剩余空间最大的卷,创建dataspool子目录,如/data/dataspool)
Windows平台,关闭360等安全软件后,仍然无法安装代理,且远程推送安装日志没有报错
该问题是因为360等安全软件拦截了VC运行时库vcredist_x64.exe的安装,导致系统状态标记为此安装包已经安装,而实际其运行时库文件却并不存在,使得后续代理安装失败。
解决方法:
登录源主机,确保360完全退出。注意其主动防御开关是在其子菜单里的选项。
请在源主机上运行vc运行库安装包vcredist_x64.exe。注意点击[修复]。
安装完毕后查看
c:\windows\system32目录下,应有多个api-ms-win-crt-*.dll文件。请在控制中心再次安装代理(推送或拉取安装)。代理应当成功安装。
Windows平台,推送安装不成功,安装日志里有多个错误,例如wmic、powershell不可用
这可能是系统环境变量PATH里删除了默认变量。请检查系统变量PATH,如果没有以下变量,请增加,然后再次推送安装。
%SystemRoot%\system32;%SystemRoot%;%SystemRoot%\System32\Wbem;%SYSTEMROOT%\System32\WindowsPowerShell\v1.0\;
也可以使用拉取安装来避免此类环境设置问题。
Windows主机推送安装代理失败,安装日志显示"Authentication (publickey) failed"或"Exception: the specified credentials were rejected by the server"
请使用下面任意一种适用的方法解决问题:
请查看主机是否加入了Windows域(domain),如果使用域账户,需要使用Domain Admins组账户进行远程推送安装。
也可以使用拉取安装方式进行安装代理。
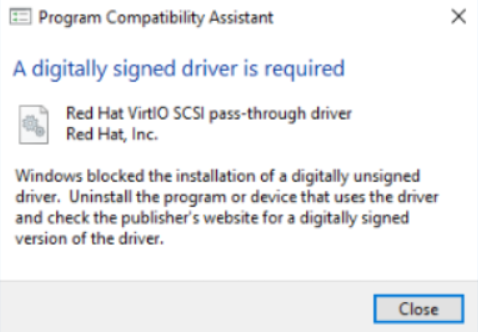
在Windows 2016及以后操作系统上安装Agent时弹出"A digitally signed driver is required"
这是因为操作系统不识别VirtIO的签名证书,需要更新系统信任证书列表。
解决方法是运行Windows Update来更新系统。此方法将更新操作系统到包括信任证书列表至最近更新。
在Windows 2008 R2等源主机上运行winrm quickconfig报出”拒绝访问“错误
首先,运行此命令需要"以管理员账户运行”;
如果仍然报错,请尝试以下步骤:
给administrator账户设置密码,如果该账户没有密码
运行以下命令添加注册表项
reg add HKLM\SOFTWARE\Microsoft\Windows\CurrentVersion\Policies\System /v LocalAccountTokenFilterPolicy /t REG_DWORD /d 1 /f重启,再次尝试运行winrm quickconfig
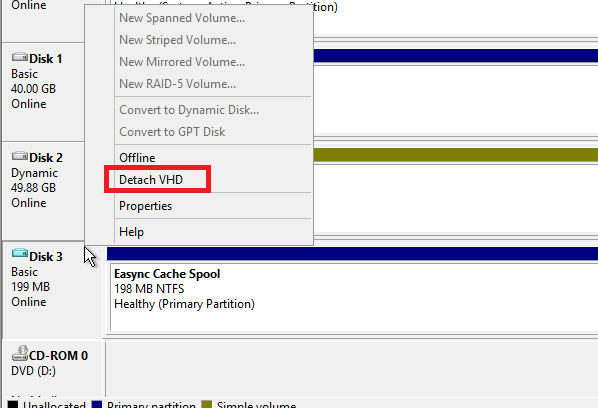
源主机或目标机状态不正常,如有红色叹号或灰色,无法运行、停止计划、不同步数据、或频繁报错发送文件失败,代理日志中包含重复的sqlite3错误
查看代理日志,包含大量错误: Failed to update db sqlite3 error: could not execute statement: database disk image is malformed Failed to update db sqlite3 error; Could not execute statement: database or disk is full
这是由于日志缓存虚拟磁盘文件损坏或异常。解决方法是停止代理,删除日志缓存目录,重启代理。
步骤:
首先,停止计划;
然后执行下列步骤:
Linux
xxxxxxxxxx/etc/init.d/easync-agent stoprm -rf /opt/cloudock/easync/agent/data/logspool/*/etc/init.d/easync-agent startWindows
停止Windows 服务
EasyncAgentService打开磁盘管理,在
Easync Cache Spool磁盘上右键,卸载VHD,勾选删除,确定。删除C:\Program Files\Cloudock\Easync\agent\data\logspool\下所有文件。启动
EasyncAgentService服务
在控制中心再次运行计划。
Debian 11需要安装linux-image-$(uname -r)-dbg包
安装代理后,驱动无法加载,这是因为Debian 11的 System.map文件不包含真实符号表,而加载驱动需要符号表信息。
xxxxxxxxxxcat /boot/System.map-5.10.0-13-amd64ffffffffffffffff B The real System.map is in the linux-image-<version>-dbg package
请在 snapshot.debian.org 地址搜索对应的Binary package 包名,下载,并在源主机安装(dpkg -i 文件名)。
例如这个对应 5.10.0-13-amd64 kernel的包: https://snapshot.debian.org/archive/debian/20220318T094809Z/pool/main/l/linux/linux-image-5.10.0-13-amd64-dbg_5.10.106-1_amd64.deb
es_sys运行报错error while loading shared libraries: libz.so.1: failed to map segment from shared object
请尝试以下步骤:
xxxxxxxxxxcp /opt/cloudock/easync/agent/bin/es_sys /tmpcd /tmpchmod +x es_sys./es_sys
如果报错permission denied,请执行以下命令:
mount -o remount,exec /tmp
然后再次尝试 ./es_sys
如果没有报错,就没问题了,可以正常创建、运行计划。
系统和依赖
整机迁移、容灾对生产机业务的影响?
本整机方案需要在生产机内安装代理,包括CDP驱动。以下为其对生产机的资源消耗和影响。其在目标机上的资源消耗略低于在源主机的消耗。
注意对于虚拟代理机(VA模式),如果有多个计划使用同一个虚拟代理机,并且多个计划同时运行,此虚拟代理机的CPU、内存、存储等资源消耗相应增高。
CPU
依据CPU性能不同,Agent对于CPU消耗大约为:数据复制阶段占用相当于单核5-10%,一些运行阶段如数据同步、创建书签、切换等,可能短时间占用相当于单核50-100%左右,并在阶段结束后回落。另外如果开启数据压缩,也会导致CPU占用轻微升高(一般单核1-2%)。
内存
Agent内存消耗大约为:在计划停止状态下,30-80MB,数据复制阶段占用约50-100MB,一些运行阶段如数据同步、创建书签、切换等,可能上升至500MB左右,并在阶段结束后回落。
I/O性能
数据同步时,将在OS内对卷创建快照,创建快照时将有一个短暂的写入高峰。快照将在数据同步期间一直存在,快照所占空间取决于生产机的数据变化率和同步时长(全量数据大小/同步带宽)。
如果是第二次同步数据,计划默认将进行数据比较同步(或手动选择比较同步)。做数据比较时,将不限制速度的读取源端数据生成hash。如果想限制对生产机数据的读速度,请在计划-源主机页面-磁盘IO限速进行设置。注意此选项进对数据比较阶段有效。
数据同步时,将不限制速度的读取源主机数据并发送。如果想限制数据同步时对源主机的IO读速度,请在计划 - 目标机 - 网络限速进行设置。
网络
在没有IO、带宽瓶颈情况下,单个计划数据同步速度可达约900Mbps(千兆网)、4Gbps(万兆网)。网络传输基于标准TCP/IP协议,如果发生网络异常拥塞、中断、丢包等,请按一般经验步骤进行排查。
硬盘空间
安装需要 / 或 C:\ 下至少有2G剩余空间用于安装。
另外还需要至少4G剩余空间,可以是 / 或 C:\卷,也可以是其他卷,用做数据缓存。
迁移后操作系统、应用软件是否需要重新激活?
迁移后应用系统,包括操作系统本身,是否需要重新注册/激活,取决于应用系统/操作系统本身的许可机制和策略。迁移过程本身可以看作是把源主机的所有数据复制到备机,不能修改主机系统以外的数据、设置等。例如,零售版Windows操作系统的激活策略是如果检测到硬件有显著变化,就会要求重新激活,而跨平台迁移整机一般都会导致网卡MAC地址、主板序列号、主机ID、CPU序列号等发生变化,导致要求重新激活。批量许可(VL)或OEM许可,以及企业环境部署KMS激活服务的场景下,情况又相应不同。一些应用系统也有类似机制。对于应用系统不绑定特定硬件标识的,在整机迁移后原理上不存在需要再次激活这种情况。简言之取决于应用、系统本身的许可机制策略,具体需要咨询应用系统、操作系统供应商。
是否支持Intel/AMD/海光CPU之间迁移?
支持x86_64包括海光C86之间的VM迁移。切换后VM是冷启动,不需要两端CPU指令集完全一致。
注意操作系统本身或应用对CPU指令集的要求。例如,RHEL 9.x之后,要求CPU支持x86-64-V2,因此此操作系统不能迁移至更老的x86_64平台上,诸如此类。
迁移后目标机和源主机数据是否完全一致?
本整机迁移/容灾方案是基于异步实时复制的CDP在线热迁方案,异步机制决定做不到任意时刻两端数据完全一致。在数据复制阶段,没有网络和IO性能瓶颈的情况下,目标机数据比源主机数据时差平均约1秒(可配置,最小时差0.1秒)。
CDP驱动无法捕捉内存中的数据,在点击切换时,源主机有正在运行的应用,包括进行中的数据写入操作,这些数据将不会被复制到目标端,造成数据不一致。所以,总是建议在切换前,停止源主机上的应用服务,以便将缓存中的数据刷到硬盘,被驱动捕捉并传到目标端,然后再开始切换。这种情况下,应用数据为静态数据,两端完全一致。
对于操作系统本身,同样存在系统文件/注册表/内部数据库等自动更新,切换操作本身,相当于一次操作系统断电重启。断电会造成内存中的数据丢失;磁盘缓存中的数据可能丢失或损坏;正在写入的数据的可能部分写入,导致文件损坏;文件系统元数据也有可能处于不一致状态。
目标机启动后,操作系统将进行自我修复,包括需要引入手动干预(chkdsk/fsck),甚至关键系统文件损坏的情况下,可能需要通过介质恢复。
当出现切换后操作系统启动失败、运行异常等,可以尝试关掉业务应用、非关键系统应用后进行再次迁移。
是否同步全盘大小的数据?
整机方案的数据同步基于卷,不是基于硬盘。一个硬盘可能有多个卷,不选择的卷不进行数据同步。
数据同步基于卷的有效数据块,而不是全卷。例如
/data或D:\卷 100GB,有效数据只有30GB,那么将只同步30GB数据。注意,
rhel4、5由于kenrel太老,只能同步全卷,如上例子,将同步100GB。个别特别新的kernel也可能会同步整卷数据。对于Windows平台总是同步有效数据。计划运行时会自动创建数据缓冲区(2-64GB),在
Linux平台上,这个数据缓冲区也将被同步。在Windows平台数据缓冲区不被同步。对于通用模式,目标机虚拟磁盘是用户端自主创建,精简置备或厚制备是创建时选择决定;对于虚拟化模式,是否精简置备或厚制备取决于备份目标的属性设定,虚拟代理机(VA)将按照此属性设定创建目标机虚拟磁盘。
在数据复制过程中如何对源、目标两端数据进行一致性对比?
本整机迁移、容灾方案基于卷块级数据处理,不是基于文件级方案。在数据复制过程中,目标端磁盘以离线方式挂载,无法以文件方式挂载并查看文件。另外,对整机方案来说,生产端是一个活跃的主机,包括应用系统在内的数据时时刻刻都可能在改变。所以在数据复制过程中,无法对整机范围内数据进行文件或数据一致性对比。
软件内置了数据一致性校验,确保数据在源端读取传输发送到目标端后数据一致。如果用户希望进行文件对比,可以通过演练、恢复、切换等功能,在目标机拉起后,选择一些当前时刻数据不发生变化的文件进行对比。
是否支持断点续传?
整机迁移、容灾产品在数据传输过程当中,如果发生网络中断,那么代理将无限等待网络重连,然后接续发送上一个数据块,实现断点续传。
注意,无论网络是否中断,如果有一方代理服务发生重启(例如主机重启、手动重启代理服务等),计划将自动停止,不再进行数据复制。如果需要继续同步数据,需要再次运行计划。再次运行计划时默认会对两端进行数据块级比较,只传输差异数据。
是否需要/如何进行二次增量同步?
产品是基于CDP,也就是持续数据保护,源主机不停服务、不停机。只要计划处在运行状态,生产服务器上的增量数据会被CDP驱动实时捕捉,并异步传输到目标端。不需要传统基于备份的迁移技术里的“二次增量同步”操作。
点击“切换”按钮后,计划将停止。从这一点开始不再捕捉、复制源主机上的数据变化,目标端数据不再进行更新。
切换后,如果确实需要重新做数据同步,再次运行计划即可。对于通用模式,需要将目标机重置为RamOS(迁移场景)或容灾操作系统(容灾场景),再运行计划;对于虚拟化模式,如果备机虚拟机正在运行,将提示用户手工关闭目标机再运行计划,以防止误运行而将正在运行的目标机覆盖。
再次运行计划默认会对两端进行数据块级比较,只传输差异数据。
切换前源主机可以关机吗?
可以,但不建议。当计划在切换准备就绪状态,随时可以切换,不受源主机是否在线状态影响。
不建议切换前手动关机是处于数据一致性考虑。因为关机时,Easync代理服务和驱动也被关闭了,无法保证数据库、容器缓存数据落盘并且完全复制到目标端,可能会造成数据不一致。对于源主机运行数据库、容器等应用,请参见 切换窗口 处理切换的数据一致性。如果有源主机自动关机的需求,可以在计划的目标主机标签页,选择[切换时源主机关机]并保存。
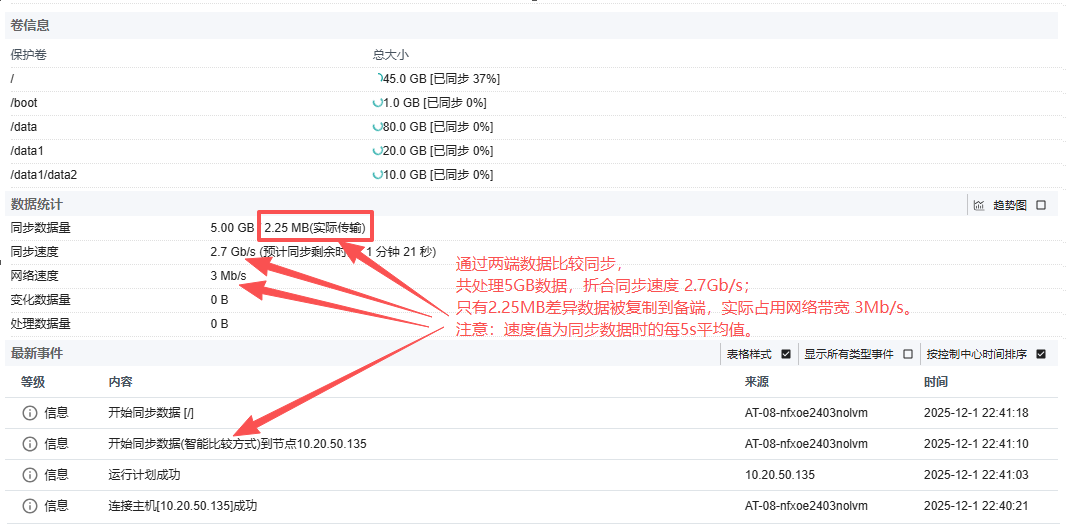
统计信息中显示的数据压缩率是怎么计算的?
计划右侧显示的统计信息中的压缩率是 数据压缩后大小 / 数据原始大小 。例如,原始数据100MB,压缩后40MB,则同步压缩率显示 40%。
对于用户生产服务器来说,影响数据同步的数据压缩率常见有以下因素。
数据类型。对于生产服务器数据主要包含视频、音频、图像、压缩文件等,那么数据可压缩程度很低,这里显示的压缩率将很高,例如90%;对于用户数据主要是文本文件、日志、数据库(稀疏文件),数据可压缩程度很高,这里显示的压缩率甚至可以达到个位数。不同数据源的数据压缩率受数据类型影响。
压缩算法。压缩算法通常分等级,压缩程度通常和CPU占用率成正比,压缩程度越高,CPU消耗也越高,同时也消耗更长时间;反之亦然。本产品采用的压缩算法默认为中值,在压缩率和CPU消耗占比取得较好的折中。
通常建议在广域网传输时启用数据压缩。在局域网内,通常带宽很高,启用数据压缩带来的数据减少效益不高,而且带来CPU开销。
另外,本产品同步时可以选择同步比较,两端数据将进行对比,只传输差异数据,在这个基础上,配合数据压缩,将显著减少实际传输的数据量,更快完成数据同步。
数据同步速度太慢或太快?
在网络、存储性能没有瓶颈的情况下,单个迁移、容灾计划的同步速度在万兆网环境下可达4 Gbps;千兆网环境下可达900 Mbps。
数据实际同步的速度和源端I/O 4K随机读、256K顺序读、目标端IO 4K随机写、256K顺序写性能、源端数据块碎片化程度、网络可用带宽、网络质量等相关。
如果同步速度较慢,请首先使用第三方磁盘性能测试工具、网络测试工具等在源主机和目标机/VA操作系统内进行测试以上指标。
下面是Linux平台使用fio测试。Windows平台命令类似。
源端
xxxxxxxxxx#4k随机读fio --name=randread_4k --ioengine=libaio --rw=randread --bs=4k --size=1G --filename=/dev/sda --direct=1 --iodepth=1 --runtime=30 --time_based --group_reporting#256k随机读fio --name=seqread_256k --ioengine=libaio --rw=read --bs=256k --size=2G --filename=/dev/sdX --direct=1 --iodepth=1 --runtime=60 --time_based --group_reporting
目标端
xxxxxxxxxx#4k随机写fio --name=randwrite_sync_4k --ioengine=sync --rw=randwrite --bs=4k --size=1G --filename=/path/to/testfile --direct=1 --fsync=1 --runtime=60 --time_based --group_reporting#256k顺序写fio --name=seqwrite_sync_256k --ioengine=sync --rw=write --bs=256k --size=2G --filename=/path/to/testfile --direct=1 --fsync=1 --runtime=60 --time_based --group_reporting
如果无法安装fio,可以用dd命令近似测试。注意随机读写性能一般要远远小于顺序读写性能。
xxxxxxxxxx#4k顺序读dd if=/dev/sdX of=/dev/null bs=4k count=100000#256k顺序读dd if=/dev/sdX of=/dev/null bs=256k count=10000
xxxxxxxxxx#4k顺序写dd if=/dev/zero of=/path/to/testfile bs=4k count=100000 oflag=sync#256K 顺序写dd if=/dev/zero of=/path/to/testfile bs=256k count=10000 oflag=sync
也可以模拟端到端测试:
将目标端目标磁盘某个目录以nfs方式挂载到源主机,如 /nfstest 下;
在源主机上运行命令
dd if=/dev/sda2 of=/nftest/1.dat bs=4K oflag=sync,查看同步速度。
注意此测试速度相当于源端4K顺序读的情况下的测试结果,作为大致参考。本产品的实际同步速度理论上介于4K随机读和 256K顺序读性能之间,取决于硬件本身I/O性能和OS内部磁盘数据块的碎片化程度。
数据统计页面可能会显示同步速度太快,超过了物理带宽或限速设置。这里的同步速度是源主机上扫描过的数据的原始大小/时间(每5s平均值)。不一定等同于网络实际传输速度。和是否是第二次同步(默认自动进行数据比较同步)、是否选择了比较同步有关。
要确认网络的实际传输速度,请登录源主机,查看网卡实际传输速度。
产品对网络带宽、延时要求?
关于网络带宽和延时,软件本身没有硬性要求。从生产角度讲,用户带宽应当足够传输生产数据变化量以达到RPO要求。还要考虑带宽争用共享的因素。基于CDP的原理,生产数据变化量和终端用户观察到的“硬盘剩余空间减少了多少”不一定相符,可以对计划运行【评估模式】持续几个典型工作日,来查看显示的数据变化量,进行带宽评估。
产品也支持【定时增量复制】模式,此种模式相当于增量备份,一般会减少一定数据传输量,减少幅度取决于应用服务的写方式和存储本身特性。
产品RPO/RTO指标?
产品默认工作在异步CDP模式。卷级驱动实时、连续抓取数据块改变,也就是每一个IO写操作,并将数据块变化异步发送到目标端。在没有网络、IO瓶颈的情况下,RPO平均约1秒。
关于RTO,取决于硬件性能、操作系统类型、版本不同,从开始切换到备机拉起时间一般为2-5分钟。
源主机为UEFI/BIOS引导,计划运行时可能报错缺少BIOS/UEFI依赖包
软件将尝试自动安装所需依赖包,无需人工操作。如果失败,请按如下平台手动进行安装。以下操作均在源主机上运行。
若目标机为UEFI引导
包含以下两种场景:
通用模式下,用户创建的目标机为UEFI引导;
虚拟化模式下,若源主机为UEFI引导,将自动尝试创建UEFI目标机。
源主机为CentOS 7、RHEL 7、银河麒麟v10、中标麒麟v7、UOS 20 a/e系列:(如果没有配置yum源,请在OS对应版本的安装介质中找到该 rpm 包进行安装)
x64: yum install -y grub2-efi-x64-modules
aarch64: yum install -y grub2-efi-aa64-modules
源主机为Ubuntu、UOS 20 d系列:(一般系统已经默认安装。如果系统包被精简处理过请手动安装)
x64: apt install -y grub-efi-amd64
aarch64: apt install -y grub-efi-arm64
若目标机为BIOS引导
包含以下两种场景:
通用模式下,用户创建的目标机为BIOS引导;
虚拟化模式下,若源主机为BIOS引导,将自动尝试创建BIOS目标机。
源主机为CentOS 7、RHEL 7、银河麒麟v10、中标麒麟v7、UOS 20 a/e系列:(如果没有配置yum源,请在OS对应版本的安装介质中找到该 rpm 包进行安装)
x64: yum install -y grub2-pc grub2-pc-modules
源主机为CentOS 6、RHEL 6系列:(请配置包含下述包的yum源)
x64: yum install grub2-common grub2-pc-modules
源主机为Ubuntu、UOS 20 d系列:(建议通过apt源进行安装,因其依赖包随系统更新版本复杂)
x64: apt install -y grub-pc
Linux平台为代理手动安装离线依赖包
正常情况下,Linux平台安装程序会自动安装代理所需的依赖包。如果安装出错,在安装代理、或运行计划的时候会报错。这时需要手动安装依赖包。
将控制中心主机里下述文件复制到源主机上任意同一目录下
xxxxxxxxxx/opt/cloudock/easync/cc/download/agent-needs.tgz/opt/cloudock/easync/cc/download/es_install_tools_offline.sh在源主机上述目录下,以
root或sudo运行脚本。xxxxxxxxxx./es_install_tools_offline.sh如果有报错,请根据错误信息相应的操作。
如果没有报错,请再次安装代理、或者运行计划。
RHEL/CentOS/OracleLinux 6源主机的容灾计划已知限制
当源主机为RHEL/CentOS/OL 6,容灾目标机必须为Ubuntu Server 20.04/22.04。
制作回切目标机功能不适用RHEL/CentOS/OL 6。需要手动将源主机引导到RamOS,例如使用livecd ISO启动源主机。数据恢复到源主机的情况也是如此。
创建云平台账户、或者运行计划时,出现报错"error context deadline exceeded"、"无法连接云平台"
请执行以下步骤或检查:
在CC主机上运行命令查看连接
ping <云平台-IP>curl -kL <http(s)://云平台-IP:port>docker exec -it easync-cc-virtcontroller ping <云平台-IP>如果是运行时VA报错,在VA上运行同样命令查看连接
ping <云平台-IP>curl -kL <http(s)://云平台-IP:port>CC、VA的本机时间要准确。注意时区。和云平台时间相差过大将导致API调用失败。
源主机、虚拟代理机(VA)的agent版本要相同(或接近,建议总是升级到相同版本)。版本相差过大也可能导致报错“无法连接到云平台”。
云平台其他安全策略、白名单、黑名单等设置。
是否支持集群的迁移
Easync整机方案可以近似的看作复制了一份主机镜像,本身不去感知、识别主机是否是独立单机或集群成员。每一台集群成员主机都作为一个单机进行迁移。切换后,在灾备端是否需要对集群进行配置调整取决于集群本身的属性、设置等。本方案已经应用于很多K8S、Hadoop、MySQL等集群迁移项目。集群迁移一般有如下考虑建议:
迁移计划中,目标机网络设置部分,建议保持源主机IP地址不变。集群成员主机IP地址变化后可能需要对集群进行相应的调整设置。
一般建议先切换主节点,主节点备机启动后,再切换从节点、其他节点。
对于K8s集群,因为有的云平台会自动启用swap,所以切换后需要在目标机上运行
swapoff -a,再重启containerd或机器,否则容器服务可能无法启动。基于共享存储的集群,取决于存储本身的连接方式、存储本身是否随机迁移、或单独迁移等具体情况,本整机方案对某些场景可能不适用或有限制。
是否支持迁移共享卷
关于共享存储,此整机方案支持迁移和复制以本地硬盘方式呈现在操作系统内的存储,例如 iSCSI/FC 挂载的 SAN/NAS 远程块设备。
CIFS/SMB/NFS 客户端挂载到本地的目录和挂载点,不是本地存储设备,只是一个共享目录,不支持迁移和复制。
整机迁移、容灾方案按节点授权计数方法
按节点数量许可是针对源主机,也就是待迁移、容灾的,安装了Easync Agent的虚拟机或物理机。不针对目标机/虚拟代理机。
运行计划才会消耗许可。只创建计划不运行不消耗许可。
新添加主机到源主机页面的,算一个新主机。新主机创建计划并运行,就会消耗一个许可。
如果删除了之前的源主机,又将同一个源主机再次添加进来,算一个新主机。
已经通过推送安装添加了源主机,又通过拉取安装添加进来的;或者先拉取后推送安装的,算一个新主机。应当只保留一个主机,只选择一个主机创建计划。
同一台源主机可以迁移、容灾多次,创建多次迁移、容灾计划(删除旧的计划),迁移、容灾到不同目标主机/平台,都只消耗一个许可。
迁移计划的演练、容灾计划的演练、恢复、回切不消耗许可。
怎样将目标机启动到RamOS系统?
Easync RamOS镜像是指基于winpe和 Ubuntu livecd定制的内存操作系统镜像,内置Easync Agent等程序。进行通用模式迁移、演练、恢复、回切时,都需要将目标机启动到RamOS系统。以下几种方式都可以将迁移目标机、演练目标机、回切目标机、恢复目标机启动到RamOS。请任选最适用的方式。
直接用ISO文件、光盘、IPMI方式启动目标机。物理机和大多数虚拟化平台和私有云支持这种方式。
某些云平台,支持用ISO文件制作ISO镜像,然后从该镜像创建VM,开机即直接启动到RamOS。
在Windows、Linux的普通主机上运行prepare-target程序,将自动重启进入RamOS。
支持两种方式:
通过GUI 迁移目标机 - 添加迁移目标机 - 制作迁移目标机,完成后主机即自动重启到RamOS
手动下载或复制prepare-target程序到主机上运行,主机即自动重启到RamOS
具体步骤请参见启动到RamOS系统。
支持同时运行的计划数量是多少?
控制中心
控制中心没有软件限制同时运行的计划数量。运行中的计划需要消耗控制中心以及web客户端的CPU、内存、网络等资源,运行计划数越多,消耗资源也越多。
通常一个4C8G的控制中心同时运行50-100个计划,取决于主机的CPU、内存性能;对于100个计划以上,建议分配8C16G或更多。
web客户端主机的性能也影响计划的统计数据、心跳、事件等刷新显示。
虚拟代理机(VA)
对于多个计划共用同一个VA,并同时运行计划,一般建议源主机 : VA 不多于 10 : 1 ,或源主机的硬盘总数:Linux,不多于20;Windows,不多于15(全闪环境)。如果是混闪或机械盘,请进一步减少。
同一个VA上同时运行的磁盘数过多,当运行、停止、切换、演练时,动态挂载、卸载磁盘的操作时间将明显拉长。在Windows上尤其明显。运行计划或停止计划时,可能会经常看到挂载磁盘失败、卸载磁盘失败相关错误。这个错误可以在计划的日志窗口看到,在虚拟化平台侧也应该有相关错误。另外,如果在VA里打开磁盘管理,则可以看到界面要花数分钟或更长时间才能列出磁盘信息。出现这种情况,就意味着该Windows VA无法及时响应动态挂载、卸载磁盘的请求了,请创建新的VA,将计划分配到新的VA上。
容灾目标机
对于数据级容灾目标机来说,多个源主机可以备份到同一个容灾目标机。产品本身没有限制同时运行的计划个数。需要考虑单台目标机的CPU、内存、网卡、虚拟硬盘的格式(raw、qcow2等)、后端存储是否全闪、混闪、机械硬盘、I/O性能指标等。
如果运行的计划长期出现目标端数据缓存堆积,则应考虑改善上述性能指标,或将计划分散到新的容灾目标机。
网络和防火墙
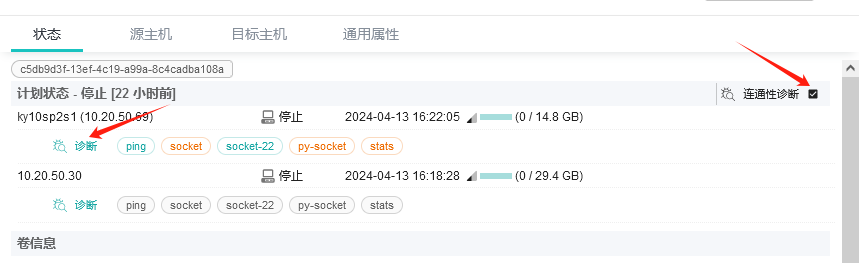
控制中心页面上源主机、目标机的连通性诊断
选择计划,选中右侧连通性诊断,点击诊断,稍候几秒钟,查看下列测试结果。
注意:如果所有项目都不通过,请按此步骤排查控制中心容器网络。
| 项目 | 行为 | 排查步骤 |
|---|---|---|
| ping | 控制中心 ping 主机 | 检查主机是否在线 |
| socket | 控制中心测试连接主机的agent工作端口 1984 (如果是源主机无法连接目标机的,按相同步骤排查,端口连接命令在源主机上运行) | 1. 检查防火墙、安全组端口设置 2. 检查 agent是否安装、运行Linux:ps aux|grep es_agentWindows:任务管理器es_agent.exe3. 检查 agent是否监听端口Linux:netstat -antlp|grep 1984Windows:netstat -ano|find "1984"4. 如果 agent没有运行,启动agent服务Linux: /etc/init.d/easyc-agent restartWindows: 在服务控制台启动EasyncAgent服务5. 如果服务启动失败,或启动后 agent进程死掉Linux:cd /opt/cloudock/easync/agent/bin; ./es_agentWindows: cd "C:\Program Files\Cloudock\Easync\agent\bin\" ; es_agent.exe观察进程启动过程日志,进程退出时的报错,截图 6. 检查端口是否可连接(运行: ssh -v -p 1984 主机IP,输出应包含connection established)7. 如果1984端口无法连接,可以尝试其他知名端口(例如 Linux上的22,Windows上的5985),来判断是网络问题,还是agent问题 |
| socket-22 | 控制中心测试链接主机的ssh端口22 (Windows不适用) | 主机是否在线,ssh服务是否运行、可连接 |
| py-socket | 控制中心解析主机名(如果使用主机名)并测试连接主机的agent工作端口 1984 | 主机名是否可解析(DNS、hosts文件) 上述socket测试排查项 |
| stats | 控制中心测试获取主机的统计信息 | 该测试检查是否能获取到agent的关于计划统计信息。如计划未曾运行,或主机重启、重置目标机,此项测试结果可忽略 |
注意:如果连通性诊断没问题,但运行前检查仍然报错无法连接主机,请确认主机上的代理是否手动安装,请控制中心证书复制到主机上,重启主机代理。证书路径请参见手动安装代理部分。
如果一切正常,则各项测试均为绿色。

如下图,socket、py-socket测试项黄色,表示失败,可以按照上表进行相应的排查。
开启了iptables的CentOS 6主机重启后控制中心可能无法连接Easync代理
Easync代理安装时会自动添加防火墙规则。CentOS 6主机重启后防火墙规则可能会丢失。请运行如下命令,控制中心即可连接Easync代理。
iptables -I INPUT -p tcp --dport 1984 -j ACCEPT
Easync liveCD如何设置静态IP
如果主机本身设置的静态IP,且是用prepare-target方式启动到ramos,将自动设置ramos的IP为之前的静态IP。如果使用ISO镜像启动且网络没有DHCP服务的话,需要手动设置IP。
Easync liveCD基于Ubuntu 18.04、20.04、22.04,请使用如下方法设置静态IP。请替换示例中的网卡名字(如ens192)、IP等为实际设置。
创建文件:vim.tiny /etc/netplan/00-installer-config.yaml
添加如下内容:
注意:每一行冒号: 和后面的字段间保留一个空格,否则报格式错误。
注意:要使用vim.tiny,不要使用 vi,因其内置快捷键和常用版本vi不同,容易误操作。
xxxxxxxxxxnetwork:version: 2ethernets:ens192:dhcp4: noaddresses: [10.20.51.245/23]gateway4: 10.20.50.1nameservers:addresses: [10.20.50.2]
保存退出后。运行命令:
netplan apply
Easync WinPE如何设置静态IP
请在WinPE界面左下角点击 Tools -> 网络设置
在弹出的对话框中指定静态IP,点击确定即可。
Windows容灾目标机添加主机解析记录
请用记事本编辑 C:\Windows\System32\drivers\etc\hosts 文件,参照示例添加所需的主机解析记录,保存,退出即可。
Easync WinPE添加主机解析记录
在Easync WinPE界面,点击左下角 Tools -> Run,输入 cmd,回车。
运行命令
notepad drivers\etc\hosts,记事本将打开 hosts文件,参照示例添加所需的主机解析记录,保存,退出即可。
控制中心或源主机无法连接目标机、无法获取目标机信息
在目标机上运行
netstat -anlp|grep 1984,查看代理是否有监听端口。
如果没问题,下一步;
如果没有监听,运行 /etc/init.d/easync-agent restart 重启代理;
如果有监听但进程名不是 es_agent,则是端口冲突。需要修改 /opt/cloudock/easync/agent/data/es-cfg.json ,port 1984为另一个未使用端口,如28000,然后重启代理;并且在控制中心UI上更新目标机连接端口;
从目标机同网段/交换机, 找另外一台机器,
ssh -v -p 1984目标机ip, 查看是否包含connection established。
如果包含,下一步;
如果没有包含 connection established,则代表连接目标机代理失败。排查步骤一般请尝试:
a. 目标机自身IP是否正常,是否可以ping别的主机;
b. 目标机OS内防火墙是否允许1984端口(iptables -L INPUT -n);
c. 重启目标机代理 /etc/init.d/easync-agent restart
从CC、源主机分别运行上面命令连接目标机代理。
如果无法连接,请排查CC、源主机 到目标机 IP、端口的网络设置、防火墙等。
SMTX验证云平台账户、创建备份目标时无法列出集群信息、或计划运行时错误,后台日志报告401错误
virtcontroller报错:response status code does not match any response statuses defined for this endpoint in the swagger spec (status 401)
如果SMTX平台上设置了白名单,需要将控制中心主机、虚拟代理机加到白名单。否则会连接云平台失败。
目标网络设置
使用基于云平台的网络设置时,例如IP漂移,网卡漂移,无法获取某一个节点的系统信息,但云平台账户设置和代理连通性验证都没问题
尝试重启该节点的代理服务,再次尝试。
主备切换
源主机和目标机之间的BIOS/UEFI相互转换支持情况
通用模式
当目标机的启动方式(BIOS/UEFI)与源主机不同,切换操作会尝试自动转换为目标机启动方式。以下为支持自动转换的配置。
源主机为BIOS,所有操作系统均支持目标机同为BIOS。
源主机为Windows Server 2012 - 2019,目标机支持BIOS/UEFI自动相互转换。
源主机为Windows Server 2008 R2,不支持BIOS(源主机)转换为UEFI(目标机),支持UEFI(源主机)转换为BIOS(目标机)。
源主机为CentOS/RHEL 6 - 8,支持源主机UEFI转为目标机BIOS;不支持BIOS转UEFI。
源主机为CentOS/RHEL 6 UEFI,仅支持源主机UEFI转为目标机BIOS。不支持目标机为UEFI。
源主机为Ubuntu Server LTS 18.04 - 20.04,支持源主机UEFI转为目标机BIOS;不支持BIOS转UEFI。
虚拟化模式
在虚拟化模式,虚拟代理机将自动创建备机,启动方式与源主机保持一致,除了以下例外。
如果源主机为Windows Server 2008 R2 UEFI, 在SMTX超融合平台,将自动创建备机为BIOS启动方式。
Windows 2012 R2 EFI启动的源主机,在虚拟代理模式切换后,虚拟机显示grub启动选择界面,选择RHEL/CentOS后无法启动
已知一种情况是,源主机为EFI启动,之前安装Linux,后安装Windows,但是在Windows安装界面没有将之前的EFI分区删除。所以EFI分区内保留了之前grub启动相关设置。
有以下两种方法解决,选择其一即可:
建议重新安装源主机操作系统,清除所有之前系统遗留的分区。然后重新运行迁移、容灾切换。
如果不能重装操作系统,也可以在灾备虚拟机上执行下面命令进行修复:
在grub启动选择界面,按
c进入grub程序执行命令,查找期望启动的操作系统目录的引导文件
lsls (hd0,gpt1)set root='(hd0,gpt1)'chainloader /efi/Microsoft/Boot/bootmgfw.efiboot注意,如果你的环境启动分区不是在
hd0或gpt1,请尝试遍历现有硬盘和分区,定位到efi引导文件。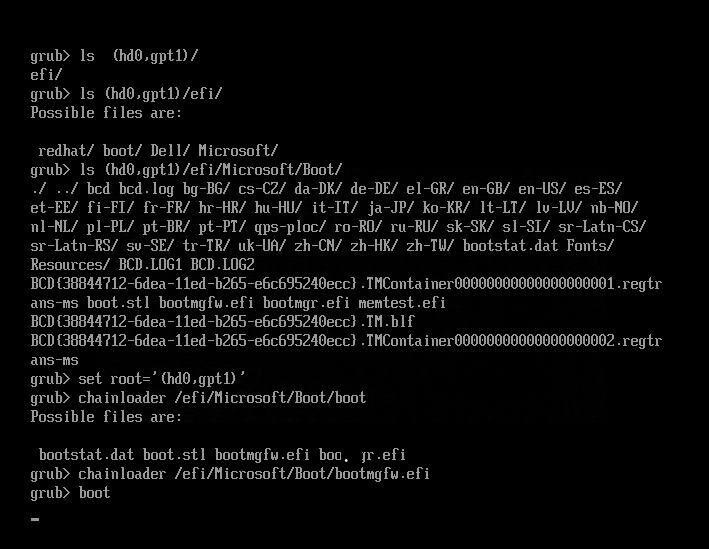
系统将成功启动到Windows 2012 R2.
Windows域控(Domain Controller)源主机,AD数据库NTDS、SYSVOL目录安装到了C盘以外的盘符,切换时目标机启动蓝屏
对于Windows 2022之前的版本,在VM启动时反复按F8,选择Active Directory Repair Mode,确定。系统应当成功启动到安全模式。
此时无需登录,等待其自动重启,无需操作,系统应当自动启动到正常模式。
对于Windows 2022,可能无法按F8选择启动模式。
登录源主机,运行命令
msconfig,选择启动 - 安全模式 - Active Directory 修复。点击应用按钮。注意不要点击现在重新启动Windows,否则主机将重启!
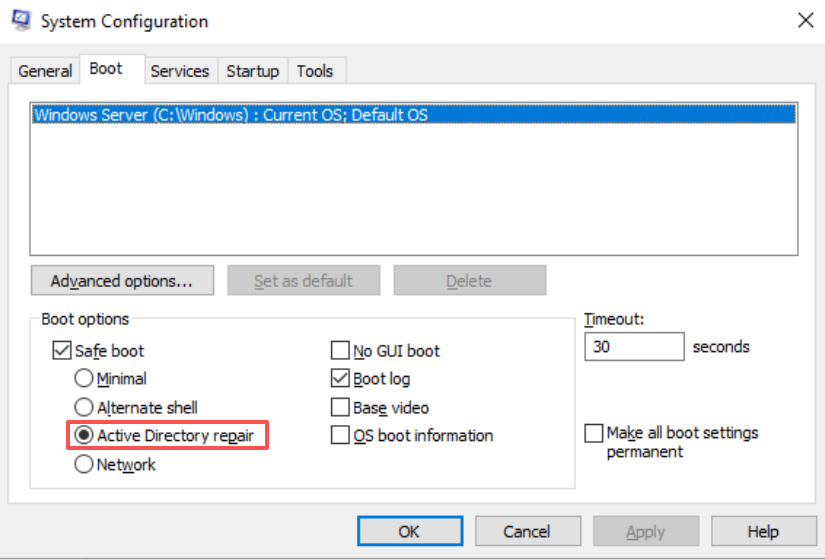
重新运行计划,同步数据,点击切换。系统应当自动启动到安全模式。
此时无需登录,等待其自动重启。
重启后登录目标机,运行命令
msconfig,选择启动,取消选择安全模式,点击确定,点击重新驱动Windows。登录源主机,按同样操作取消安全模式,点击不重新启动Windows。
数据同步完成但一直没有进入切换准备就绪状态
确认数据统计部分的【处理数据量】和【变化数据量】已经达到一致且不再快速增加。数据同步过程中系统产生的变化数据也会被捕捉并复制到备端,到数据同步时刻之前的所有变化数据都复制到备端后,才能进入切换就绪状态。如果处理数据量 < 变化数据量,请等待变化数据复制完成。
如果处理数据量和变化数据量都是0,且长时间没有变化,则可能是同步结束时的发起的数据一致性快照(例如在Windows平台上对卷组创建的VSS快照)调用没有返回,所以后续的数据一致性书签也没有下发,导致无法进入切换就绪状态。注意这是系统行为导致,正常系统创建快照一般在60s内返回。
遇到这种情况,请下载代理日志,并附截图发送给技术支持人员,进一步排查确认问题。
注意:在正式切换前,对于源机运行数据库或其他使用大量缓存机制的应用,包括像系统一致性快照不能及时返回的特例,一概建议停止应用服务,确保缓存落盘,并且复制到备端,再进行切换。 具体操作请参考此文档。
灾备机启动过程中磁盘扫描程序无限滚动报错Deleted invalid filename xxx in directory xxx
请重启机器,在提示需要进行磁盘检查时按任意键取消磁盘检查,然后登录操作系统。
对系统盘C盘以外的每一块硬盘上点右键 》属性 》工具 》开始检查 》开始,进行磁盘查错,依次进行。
请确认扫描无错误,或有错误但系统自动修复。
最后对C盘同样操作,系统将在下次启动时进行检查。
重启机器。等待磁盘检查完成。
切换后目标机硬盘使用空间和源主机不一致
一般有以下因素,请逐一排查。
Windows平台上,系统的System Volume Information隐藏文件夹内有VSS快照会占用空间。System Volume Information目录在每个盘符的根目录下,默认隐藏,需要打开文件夹选项 - 显示隐藏目录、不选中隐藏受保护的操作系统目录,确定,就可以看到这个隐藏目录。还需要右键属性 - 安全 - 编辑,添加管理员或everyone给与只读权限,确定,然后右键此文件夹,属性,就可以看到目录占用空间大小。
对于迁移计划,切换后默认会卸载代理。如果代理卸载失败,那么数据缓存将可能遗留,占用空间,请参见安装升级手册手动卸载。
注意:对于容灾计划,请勿手动卸载代理!除非确定后续不再使用本产品进行恢复、演练、回切等操作。
RHEL/CentOS 6迁移,如果OS没有单独/boot分区,而且目标机系统盘>=2TB,切换后备机可能启动失败,进入grub shell
这是一种问题配置,如有可能,请作如下任何一种修改:
给源主机添加独立的/boot分区。请参考系统文档做相应修改。然后新建迁移计划或修改现有计划源主机属性页的同步卷设置,确认包含新添加的/boot卷
目标机系统盘要< 2TB
RHEL/CentOS 5从其他虚拟平台迁移到KVM平台,启动后无法进入图形用户界面(X server)
迁移完成启动后,可能会看到如下界面
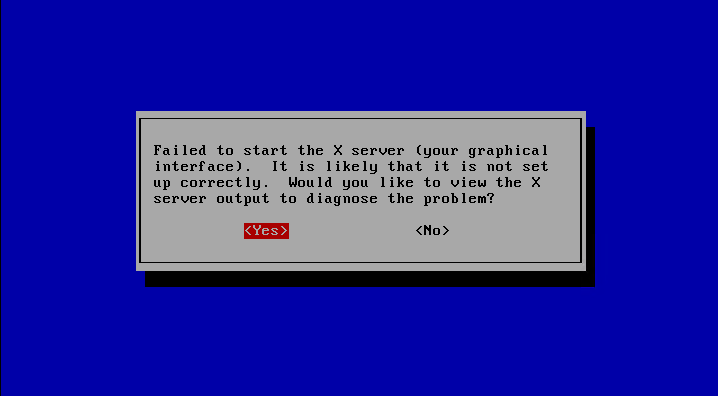
请执行以下步骤:
在这个对话框中,点击 No
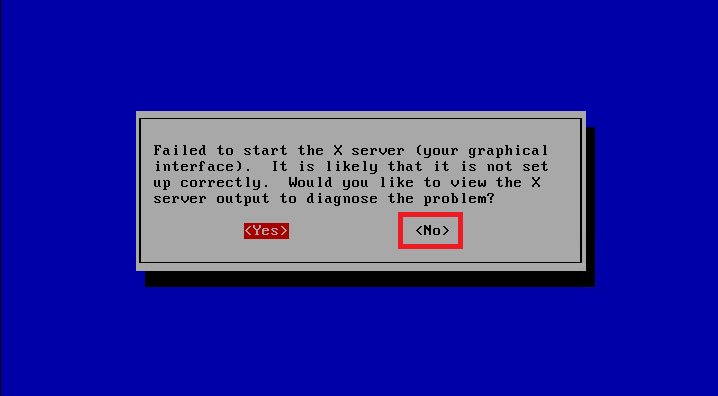
然后在弹出的对话框中,点击 Yes
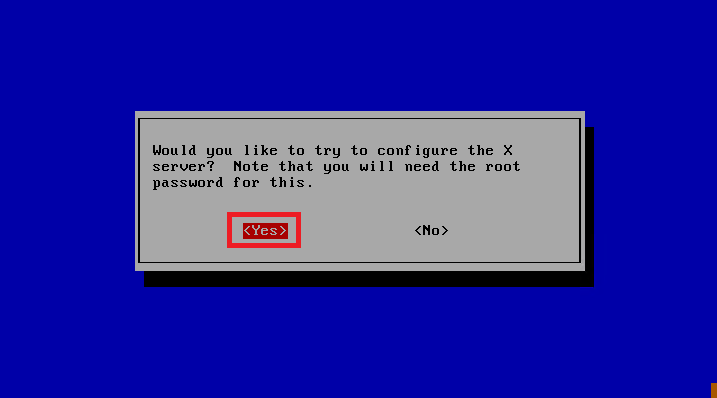
在弹出的显示设置中,可以选择适合的刷新率,点击 OK
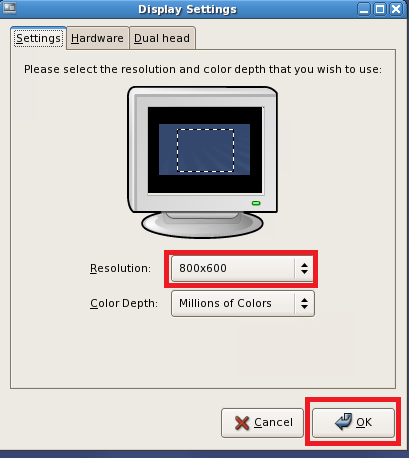
点击 OK
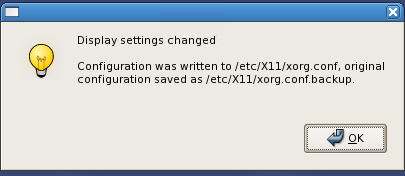
点击 OK
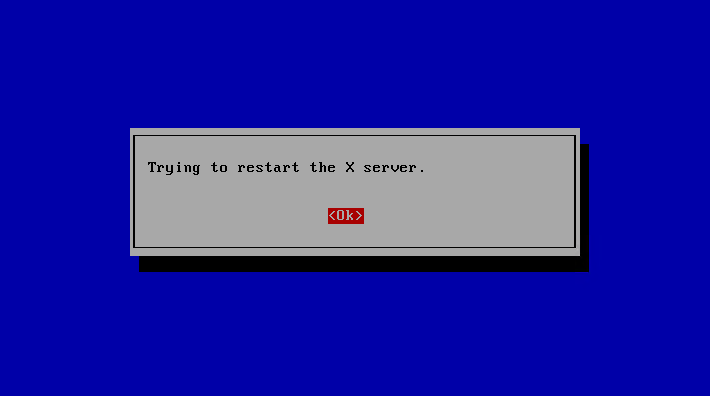
X server将自动重启,显示系统登陆界面
RHEL/CentOS 5源主机切换到KVM虚拟化平台上时,虚拟机可能出现无规律的断网
RHEL/CentOS 5.x源主机切换到KVM虚拟化平台上时,建议目标虚拟机使用Intel E1000系列网卡,而不是virtio网卡。某些5.x版本的virtio网卡驱动可能会导致网卡无规律的断网。
RHEL/CentOS 5源主机切换到KVM虚拟化平台上时,虚拟机可能出现"找不到卷组"无法启动
RHEL/CentOS 5.x源主机切换到KVM虚拟化平台上时,如果源主机的根卷(/)是逻辑卷(lv)且不在第一块磁盘上,目标虚拟机需要使用IDE控制器,而非virtio控制器。否则目标虚拟机可能出现"找不到卷组"而启动失败。
注意:如果源主机为多个硬盘组成同一个vg(卷组),则目标机对应的多个硬盘都需要为IDE接口,否则VM启动可能失败/kernel panic。
RHEL/CentOS 5源主机使用通用模式容灾切换后,如果想把目标机启动到容灾目标机自有OS,需要手动在grub菜单选择
对于RHEL/CentOS 5通用模式容灾切换后,运行recover_target_os.sh可能出错。请手动选择grub菜单以便启动到容灾目标机自有OS。
RHEL/CentOS/Oracle Linux 6源主机切换到KVM虚拟化平台上时,虚拟机可能出现"No root device found"或"LVM xxx not found"无法启动
请检查目标虚拟机的存储控制器是否为VirtIO SCSI。已知早期 6.x 版本系统没有内置VirtIO SCSI驱动,不支持从VirtIO SCSI设备启动。
解决办法:请尝试更换目标机的存储控制器为VirtIO Block、或其他如LSI SCSI控制器、IDE控制器等。
CentOS主机切换后登陆报密码错误。启动过程有Failed to start Login service错误
进入单用户模式
检查
/etc/passwd和/etc/shadow文件是否存在。如果不存在,从
passwd-和shadow-文件相应复制cp /etc/passwd- /etc/passwdcp /etc/shadow- /etc/shadow重置密码
passwd然后重启即可。
如果问题仍未解决,进入单用户模式,尝试禁止selinux,保存,重启。
vi /etc/selinux/configSELINUX=disabled
Linux源主机切换后备机启动,根文件系统/显示为只读文件系统(read only file system)
通常是根文件系统挂载异常,自动进入只读模式。请在源主机做如下检查:
检查 df 是否能列出 根文件系统 / 。如果 df 不能列出 / ,请联系操作系统提供商技术支持。
df -h检查 fstab 是否包含 / 卷。如果fstab不包含 / ,请正确添加相应条目:
cat /etc/fstab
CentOS/RHEL 4 切换后,目标机可能没有网络IP
依据目标机所在平台、以及目标机虚拟网卡型号不同,CentOS/RHEL 4目标机启动后可能由于网卡驱动、网卡型号识别问题导致不能获得IP。
请配置内置驱动的网卡型号(例如Intel E1000等),或者手动安装驱动,或者进入系统后,编辑相应的 /etc/sysconfig/network-scripts/ifcfg-xxx 文件来配置IP。
SuSE Linux Enterprise Server (SLES) 11 迁移,目标机系统盘需要为IDE总线
SLES 11迁移,目标机系统盘需要是IDE总线,否则可能无法启动。如果无法启动,请更改为IDE总线。数据盘不必是IDE总线。
通用模式高可用、容灾+高可用计划,切换后备机无法启动
请检查容灾目标机的BIOS引导设置,是否允许从数据盘引导。对不同的虚拟化平台,请检查或修改相应的VM配置界面或配置文件。
以pve为例,默认设置切换后备机无法启动,报错“You need to load the kernel first”
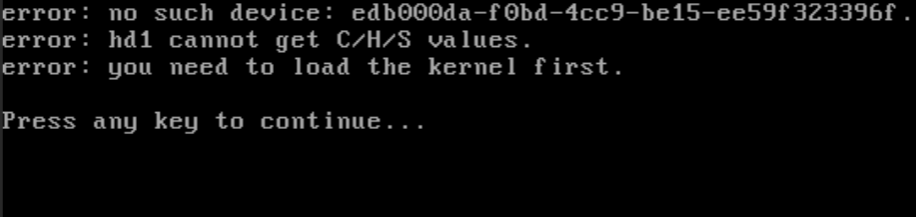
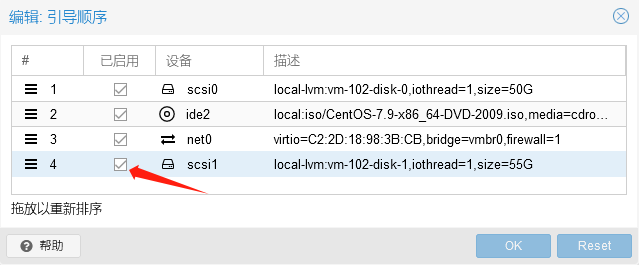
解决步骤:
备机启动失败后,关闭容灾目标机/备机。
选择虚拟机选项->引导顺序,点击 编辑,在对话框里,勾选所有的容灾盘,点击OK保存。
开机,备机就可以正常启动了。
这个步骤也可以在运行计划前执行。随后就可以正常运行计划、切换了。
虚拟化模式,SMTX目标平台,创建基于IDE的目标机
此方法针对虚拟化模式。
登录目标虚拟机,修改
es-cfg.json文件。此文件路径在Windows、Linux平台分别如下C:\Program Files\Cloudock\Easync\agent\data\es-cfg.json/opt/cloudock/easync/agent/data/es-cfg.json在此配置文件添加一行
"smartx_disk_bus": "ide",注意如果不是最后一行,行尾需要逗号(,)。保存,退出。
在控制中心管理界面,选择计划,点击工具栏->虚拟机->清理虚拟机资源。然后重新运行计划即可。目标机就自动创建为IDE磁盘。
SMTX虚拟化模式,切换后目标机VM没有安装vmtools、数据盘没有盘符、网卡没有设置IP等问题
对于SMTX平台的虚拟化模式,切换后会自动安装平台提供的svt,并设置盘符、IP地址等。如有问题请自上而下按步骤排查:
需要在
SMTX平台内容库上传SMTX_VMTOOLS名字开头的svt ISO文件。将在切换时挂载相应SVT iso,并在vm启动后进行静默安装。如果内容库没有上传对应的iso,将无法安装svt。Windows目标机内的svt静默安装卡住。这是常见问题。打开目标机内
C:\Program Files\Cloudock\Easync\agent\data\logs\es_vm_helper.log,最后日志显示"SMTX_VM_TOOLS_INSTALL.EXE /S",时间戳显示已经过去了1分钟以上,就代表svt静默安装卡住了。问题原因可能有多个。例如Windows UAC弹出确认对话框、驱动程序签名不被接受要求手动确认来源等,都会导致静默安装卡住。
手动解决步骤:
打开svt光驱,双击
SMTX_VMTOOLS_INSTALL.EXE,点击弹出的确认对话框,完成svt安装。打开任务管理器,杀掉里面现有的
SMTX_VMTOOLS_INSTALL.EXE进程。es_vm_helper服务将继续进行配置。通常会自动重启目标机1-2次,设置数据盘盘符、设置IP等。
有的源端VM安装了虚拟化平台vmtools,这些服务占用了SVT需要使用的设备如
vioserial,导致SVT安装时启动服务失败报错弹出对话框,静默安装过程被挂起。这种情况下,可以手动卸载源平台vmtools,再按上面步骤手动操作。查看网卡设置,是否已经设置了静态IP但有IP冲突等。
Windows源主机,从深信服sangfor平台迁移到其他平台,切换后VM启动可能蓝屏失败
切换后VM启动可能蓝屏、失败,或者第一次能启动成功,但后续重启可能会蓝屏失败。
目前已知,这是因为深信服VMSTool驱动与其他KVM平台虚拟机驱动或服务冲突。
解决方法是创建基于IDE的目标机,彻底删除深信服相关驱动,并安装云平台自己配套的VMTools和驱动,再改回virtio。
步骤:
指定目标机磁盘类型为IDE。
对于虚拟化模式,请登录虚拟代理机(VA),修改
C:\Program Files\Cloudock\Easync\agent\data\es-cfg.json,添加如下参数"smartx_disk_bus": "ide",注意最后的逗号(,)对于通用模式,创建目标虚拟机,添加目标机磁盘时要选择
IDE,而不是virtio类型。有的云平台需要从IDE总线的VM镜像创建目标机。
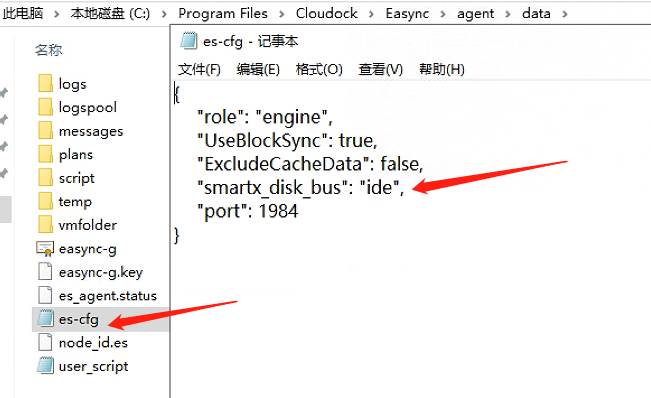
按正常步骤创建或运行计划,等待同步完成,执行切换。等待目标机启动完成。
对于虚拟化模式,如果计划已经运行过,请选择计划,点击工具栏 虚拟机 -> 清理虚拟机资源,然后再运行计划。
登录目标机,卸载深信服程序。
运行
C:\Program Files (x86)\Sangfor VMSTOOL\FastIO\uninstall.exe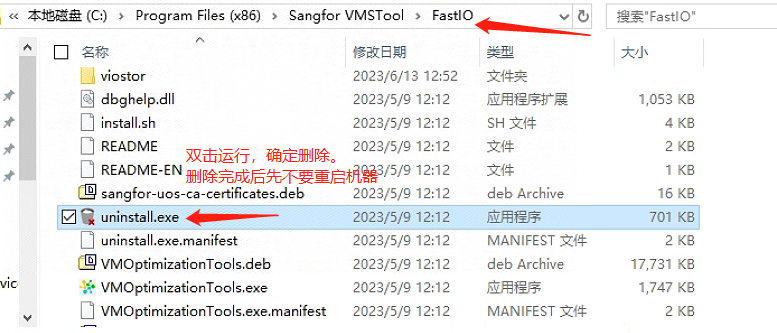
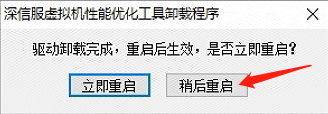
选择 稍后重启
清空文件夹
C:\Program Files (x86)\Sangfor VMSTOOL\ModulesUpdateTEMP\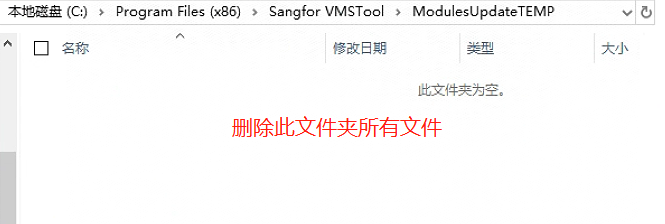
卸载深信服如下设备驱动。
选择每一个设备,右键 -> 卸载设备。
卸载完成后,重启机器。
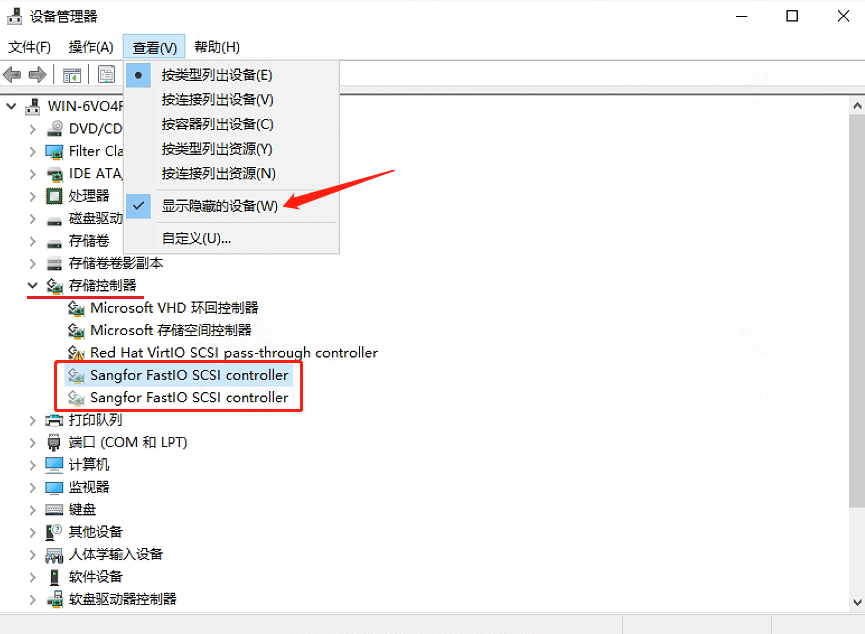
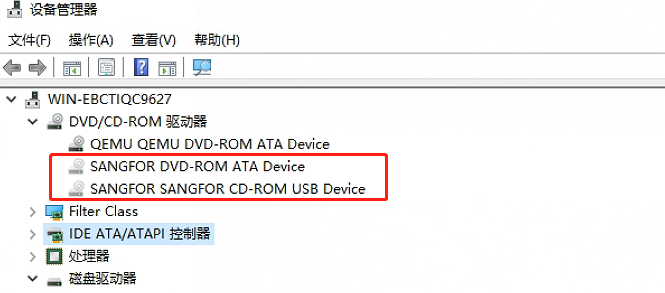
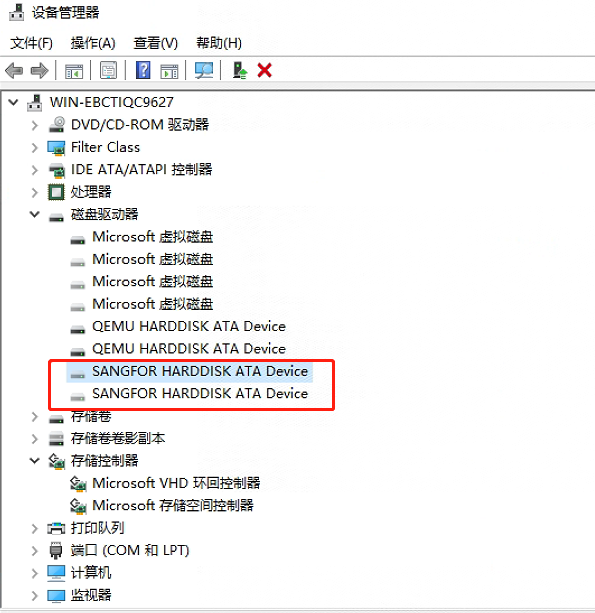
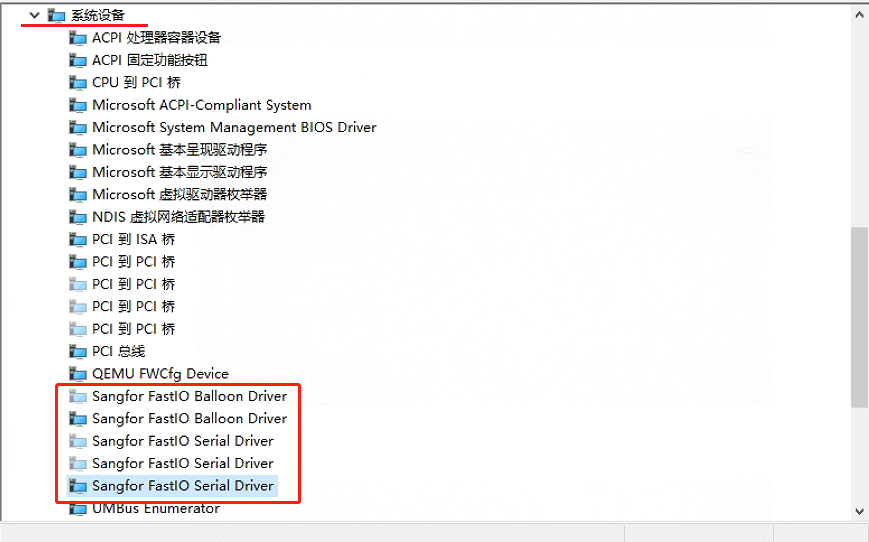
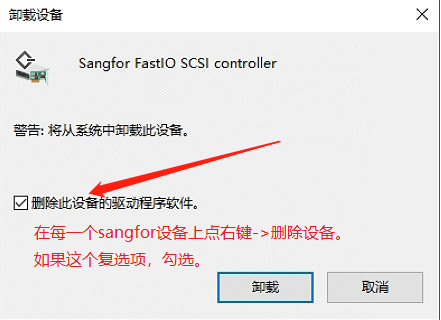
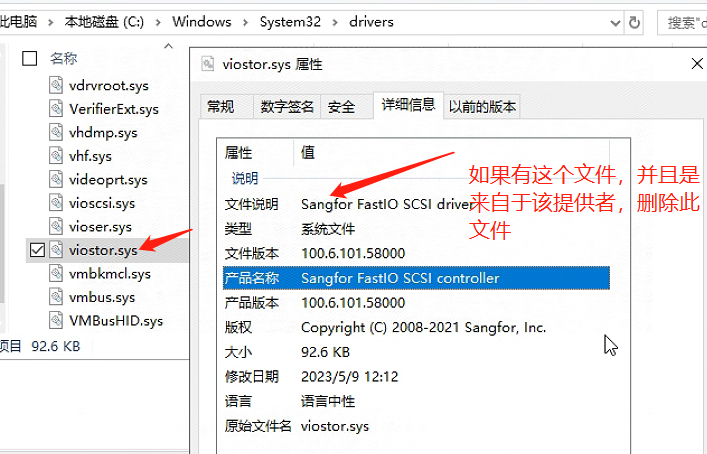
重启后,登录主机,进入
C:\windows\system32\drivers目录定位到 viostor.sys ,右键,查看属性->详细信息。如果是深信服提供,删除此文件。
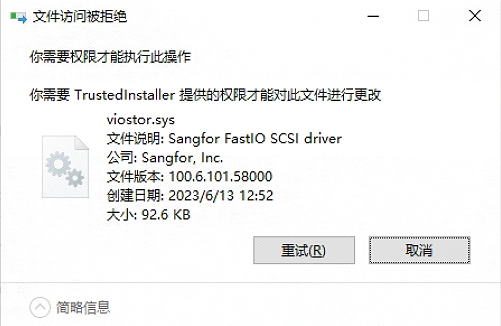
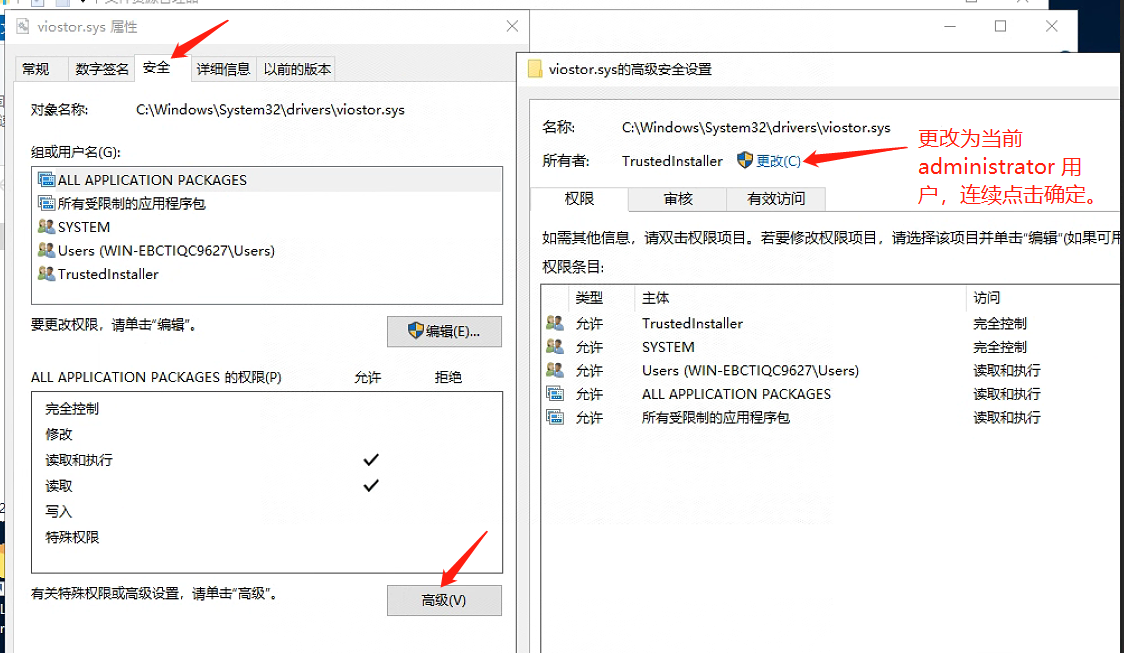
如果没有权限删除
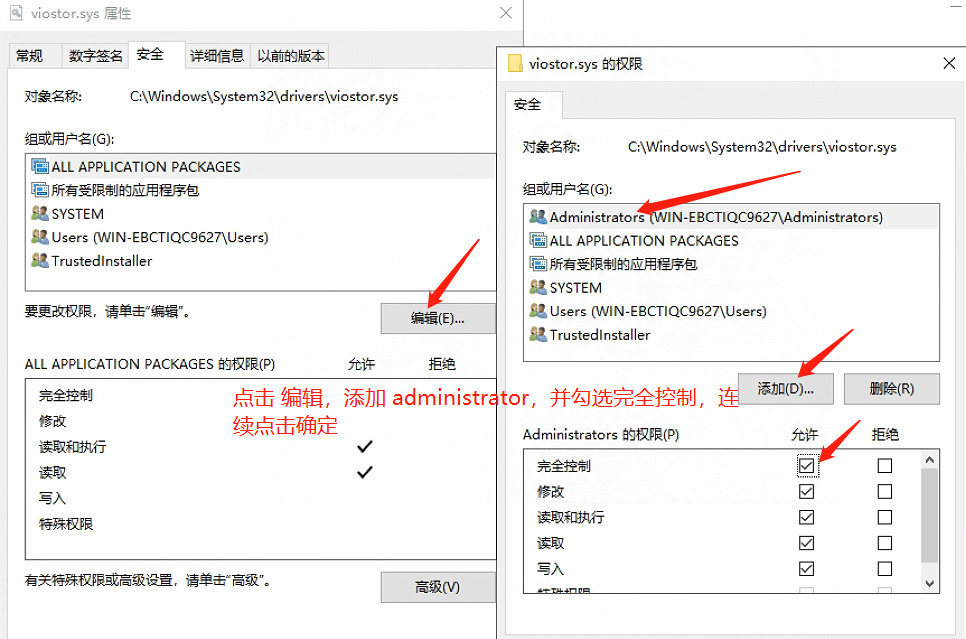
再次删除
viostor.sys文件。如果仍然不能删除,请重复检查上述步骤是否有遗漏,直到该文件被删除。
给目标机添加一块
VIRTIO类型的临时磁盘。大小随意。然后,安装云平台官方vm tools和驱动,或者公版virtio驱动和qemu guest agent。安装完成后,确认
C:\windows\system32\drivers\下vioscsi.sys、viostor.sys、vioser.sys由Red Hat提供。在磁盘管理里可以看到新加磁盘。
关闭机器。
将目标机磁盘类型改为
VIRTIO。删除临时磁盘。开机。主机应当正常启动并工作。
Windows源主机,切换后目标机上的数据库服务没有自动启动
因为Windows平台在切换时C:以外的数据盘可能由于驱动等因素需要重启后才能访问盘符或设备,而自动启动的服务例如数据库在数据盘未设置完毕之前已经尝试启动而失败。可以在数据盘可正常访问后,手动启动数据库服务;或者重新启动计算机。
切换后,目标机/备机的主机名或密码可能不是源主机的主机名或密码,而是目标机创建时的主机名或密码
请检查源主机是否安装cloud-init,并根据cloud-init官方文档进行关于主机名/密码的保留或更改设置。
源主机是CentOS 8 ext3文件系统,切换时报更新启动信息失败,查看日志是fsck错误
ext3属于较老的文件系统,目标机(VA)如果使用高版本系统如Ubuntu Server 22.04,可能由于文件系统版本差别过大导致fsck或后续其他过程失败。请将目标机换成较低版本的Ubuntu Server 20.04 ext3 或者 和源机相同的CentOS 8 ext3。
Windows平台切换如何注入其他硬件驱动?
从1.5.0-12024版本起,支持切换时对目标机注入其他硬件驱动,例如当迁移、容灾到物理机而物理机上有RAID卡,需要将RAID卡驱动注入时。
将所需注入的驱动放在源主机 C:\Program Files\Cloudock\Easync\agent\other_drivers\ 直接目录下,切换时在目标端就会尝试将其注入到目标机。
注意如不存在other_drivers目录,就新建。驱动直接放置到other_drivers目录下,从1.5.0-12228版本也支持放到其子目录下,目录名仅允许字母和数字。
是否支持Windows域控制器(DC)整机迁移容灾?
支持。注意:如果AD的Database、Log、SYSVOL目录都在 C:\卷,无需特殊操作;如果任一目录不在C:\卷,切换后VM启动可能会0xc00002e2蓝屏重启。请选择下面任一种方法解决:
VM启动时按 F8,选择 目录服务修复模式/Directory Service Repair Mode,回车,应当能成功进入系统。等待其自动重启(配置设备、安装平台工具等如果需要重启会自动重启),重启后无需再选择特殊模式。
如果无法按 F8 选择启动模式(如Windows 2022),请登录源主机,运行命令 msconfig,选择引导->引导选项->安全引导->AD修复,点确定,选择不重启,然后重新运行计划,再次切换。
切换后,目标机将自动进入目录修复模式系统。等待其自动重启,再次登录系统后,运行msconfig,取消 AD修复模式,确定,重启即可。
VA模式计划运行时报错准备虚拟化环境失败
如果计划创建后,删除了VA,又新建了VA,沿用了之前VA的IP地址,那么运行计划时就会因为根据计划里保存的之前的VA信息,查找不到之前的VA,而报错停止。
解决办法:
新建备份目标
删除原有的计划,基于新备份目标新建计划。
也可以选择当前计划,选择VA节点,然后右侧选择虚拟机标签页,更换备份目标下拉框,选择新建的备份目标,点击应用。
注意由于更改了备份目标,需要重新配置目标机网卡。
在切换后的目标机上运行自定义脚本
切换后目标机启动后,根据平台不同,将自动进行一系列操作,包括设置驱动、数据盘盘符、设置静态IP等。 可以指定脚本或命令,在上述内置过程做完后,自动执行脚本或命令。支持两种方式设置自定义脚本/命令。
针对单个计划
选择计划 - 通用属性 - 定制脚本,选择切换后目标机 - 切换后,输入命令或点击上传脚本按钮,点击保存。
针对控制中心(CC)所有计划
将命令写入或脚本重命名为如下文件,分别工作在
Linux和Windows平台上。计划运行时将发送到所有源主机的/opt/cloudock/easync/agent/data目录,切换后,目标机启动后将自动运行此脚本。/opt/cloudock/easync/cc/download/customscripts/esvm_custom_script.sh/opt/cloudock/easync/cc/download/customscripts/esvm_custom_script.bat
通用模式迁移目标机如何指定其他盘为启动盘?
通用模式迁移默认将目标机第一块硬盘作为启动盘。其他数据盘的顺序不必与源主机保持一致,程序将自动匹配映射。
有时候需要将其他位置硬盘作为启动盘,例如目标机作为物理机硬盘位置已经固定,无法重新插拔,但第一块盘大小不够源主机系统盘大小,这时候希望设置第二块、第三块硬盘等作为系统盘。
Note
有的虚拟化平台仅支持从第一块硬盘启动,不支持从数据盘位置启动;有的平台属性可以设置允许哪些硬盘启动、启动顺序等。请与平台技术人员确认平台侧设置到位。
步骤:
Linux
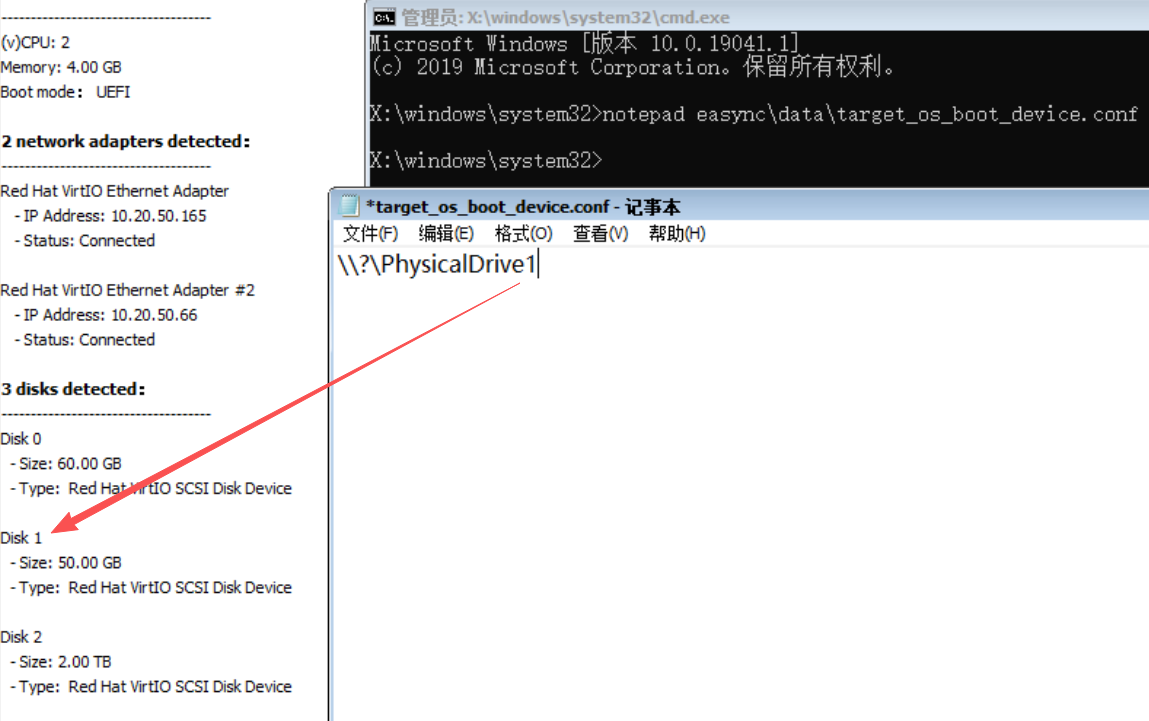
在目标机
livecd系统里,创建如下文件,内容如下,保存退出,正常运行计划,切换。/opt/cloudock/easync/agent/data/target_os_boot_device.conf内容为期望的系统盘设备路径,如
/dev/vdc这样,
vdc将成为目标机系统盘,接收源主机系统盘数据,切换后,系统将从vdc启动。Windows
在目标机
winpe系统里,点击左下角Tools - Run -cmd回车,然后如下命令,内容如下,保存退出,正常运行计划,切换。notepad easync\data\target_os_boot_device.conf内容为期望的系统盘设备路径,如
\\?\PhysicalDrive1这样,
PhysicalDrive1将成为目标机系统盘,接收源主机系统盘数据,切换后,系统将从PhysicalDrive1启动。注意硬盘路径的数字和左侧的对应关系。
整机容灾
整机容灾是否支持主机上运行多种数据库和应用?
整机方案是对包括操作系统和数据卷整体做的容灾方案,不管主机上安装、运行什么软件。本方案为卷级CDP方案,无论何种数据库和应用,对于卷级数据复制都是按数据块统一机制处理。
整机容灾一般注意两点:
启用定时书签 + 自定义脚本(使数据库、容器等数据落盘),这时 RPO实际上就是定时书签的间隔。 制作定时书签时,对于Windows源主机,会自动调用所有注册到系统的vss writer,达到数据一致性;对于Linux平台,需要配合用户自定义脚本。可以参考内置有oracle的脚本模板。 这样确保定时书签的数据一致性,但这并不意味着中间数据一定不可用,这取决于数据库、容器和应用自身特性。参见 书签
手动切换时(例如计划性的容灾演练),建议切换前停止数据库、容器服务,确保数据落盘,再切换。参见 切换窗口 另外,针对集群如k8s容灾,一般要保持IP地址不变。参见 集群切换
整机容灾方案支持的容灾类型
整机容灾方案可以分为两种级别:
数据级容灾。可以理解为全量备份+增量备份。除了传统备份模式,还支持异步CDP增量备份,RPO为IO事件级别(在不同OS上为毫秒/微妙),异步实时增量备份数据每一秒都可以进行恢复、数据演练。
应用级容灾。就是在数据级容灾的基础上还支持应急接管、拉起备机。当生产机出现故障,可以应急将灾备机拉起,接管业务。应急接管还支持从不同时间点、书签多次接管,应对原机感染勒索病毒等情况。支持在数据复制不中断的情况下对灾备数据进行演练。
数据级容灾相当于涵盖传统备份一体机的能力,应用级容灾可以给关键业务主机带来可持续高可用能力。
数据恢复粒度如何?
进行数据恢复时,数据恢复点可以选择手工书签、定时书签、或者以秒为单位的时间点。这是为便于用户操作,不列出历史数据中的每一个IO操作(微秒/毫秒级),这些数据改变是连续实时的由生产端CDP驱动捕捉。对于卷级数据块(而非文件级)异步CDP方案来说,用户选择亚秒级数据恢复点实际意义不大。
另外,产品还支持定时增量复制模式,这种模式类似于增量备份,允许增量时间间隔最小为5分钟。数据恢复点也就是每一个增量备份点。
Windows平台上数据同步和制作书签时没有调用某个VSS Writer
需要该VSS Writer服务启动类型为”自动“,且处于运行状态,才会在数据同步和制作书签时调用该服务。
注意,Windows平台上的Oracle VSS Writer服务可能会启动失败。请将该服务的启动账户改为Local System,再尝试启动。
使用prepare-target进入RamOS后不想回切、恢复数据了,如何去除RamOS系统启动菜单
Linux
重启机器,在系统启动菜单处,手动选择原有操作系统,进入系统
运行
/opt/cloudock/easync/common/restore_grub_cfg.sh如果没有报错,一般几秒钟即可完成。
这个脚本只有新版本agent才包含。如果提示没有这个文件,请将控制中心主机/opt/cloudock/easync/cc/data/script/esdr-helper/restore_grub_cfg.sh 复制到本机,运行即可。
这时候就可以重启机器了,将可以看到系统启动菜单没有RamOS,会自动选择并启动原有操作系统。
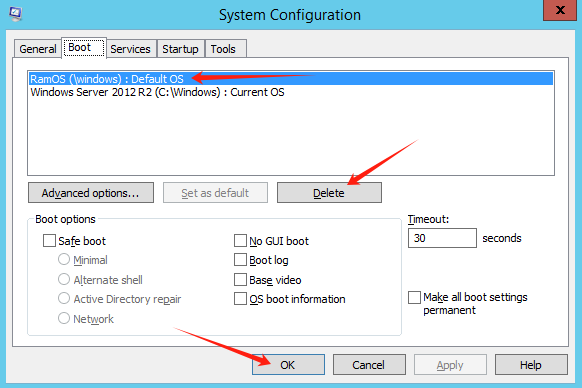
Windows
重启机器,在系统启动菜单处,手动选择原有操作系统,进入系统
运行命令
msconfig,选择RamOS行,点击删除,确定,然后选择立即重启或稍后重启机器。将可以看到系统启动菜单没有RamOS,会自动选择并启动原有操作系统。
数据库(RDS)
MySQL
如何启用MySQL binlog
MySQL binlog机制在8.0版本默认开启,对于低版本,需要更改配置文件,并重启MySQL服务。
步骤:
vi /etc/my.cnf在
mysqld字段下增加下面两行xxxxxxxxxx[mysqld]server-id=1log-bin=mysql-binsystemctl restart mysqld或service mysqld restart即可
设置binlog格式为ROW
步骤:
vi /etc/my.cnf在
mysqld字段下增加下面两行xxxxxxxxxx[mysqld]binlog_format=ROWsystemctl restart mysqld或service mysqld restart即可
设置binlog保留时间
注意,不要去手动清理binlog日志文件,否则可能会导致同步数据失败。
如果mysql默认的binglog保留时间和大小不能满足数据同步的要求,可以手动设置binlog保留时间和大小。
对于MySQL 8.x版本,可以通过以下方式设置:
步骤:
vi /etc/my.cnf具体文件名以实际为准,在
mysqld字段下增加xxxxxxxxxx[mysqld]binlog_expire_logs_seconds = 2592000 # 比如保留的binglog天数,30 天,单位是秒systemctl restart mysqld或service mysqld restart即可
中文编码字段在实时复制时可能报错
当数据库表/字段为GB18030、GB2312等,实时复制数据可能报错,计划将停止。数据同步支持这些编码,不会报错。
这是当前限制。请采用下列任一方法进行规避。
将编码改为UTF8,重新运行计划;
不改编码,但是停止生产端数据更新,然后运行计划,进行数据同步。这适用于一次性迁移方案。
打开log-bin-trust-function-creators
临时性解决:
set global log_bin_trust_function_creators=1;
永久性解决:
vi /etc/my.cnf添加
log-bin-trust-function-creators=1
缓存设置
数据缓存工作原理
数据缓存用来处理CDP驱动捕捉到的增量数据的复制,在源主机和目标机/VA上都默认使用了数据缓存。
源端
如果源主机的所有卷都被选择复制,Agent将自动创建
Windows VHD或Linux loop设备作为数据缓存。位置自动选择所有卷中剩余最大空间的卷,大小根据剩余空间自动选择 2- 64GB。位置和大小可以在计划属性中指定。如果数据缓存所在卷(通过手动指定或自动选择)不被复制,则创建普通目录作为数据缓存。空间即为该卷最大剩余空间。
数据缓存只用来处理增量数据复制,不处理同步数据,数据同步过程是从源盘直接写入目标盘,不经过数据缓存。
当源主机上短时间有大量数据写入,则有可能导致源主机缓存空间溢出。
目标端
目标机数据缓存默认使用目标机硬盘剩余空间。当源端发送增量速度较快,而目标端应用增量数据较慢、暂停(例如演练过程中),则有可能导致目标端缓存空间溢出。
当数据缓存溢出,计划将报错停止。一般情况下,可以直接再次运行计划。如果确定源主机会有周期性的数据写入高峰,可以适当设置更大的缓存空间。如果预期高峰数据量超过卷最大剩余空间,则考虑增加数据缓存盘。
如何在RamOS目标机上增加数据缓存(指定缓存盘)?
登录目标机所在的云平台控制台,给目标机增加一块虚拟磁盘。如果目标机是物理机,则需要增加一块物理磁盘。
数据缓存盘大小取决于源生产端数据变化率、全量同步所需时间(取决于全量数据量、磁盘性能、带宽等)。可以大致建议为源主机全量数据的10%~30%。
这块磁盘将专门用作数据缓存,迁移完成后可以删除。
登录目标机控制台。请按平台执行步骤
WinPE
点击刷新按钮,等待新增磁盘列出。
如下图,记住新增磁盘ID为2
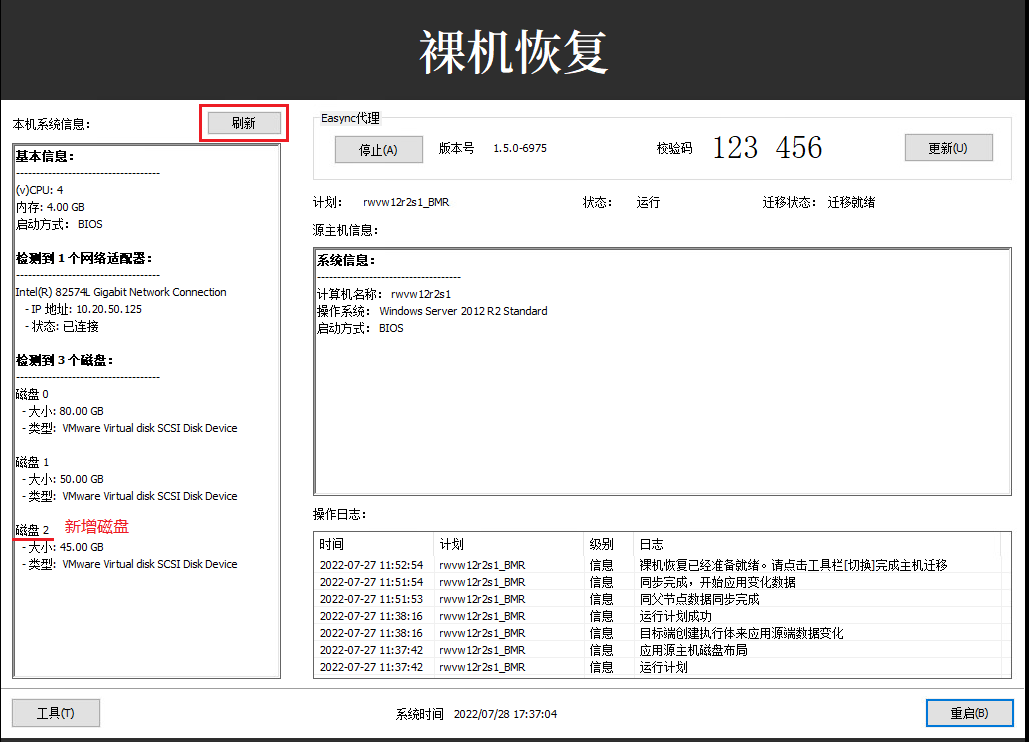
回到Easync控制中心,选择计划->目标主机,在缓存路径字段输入如下,点击保存按钮。
\\?\PhysicalDrive2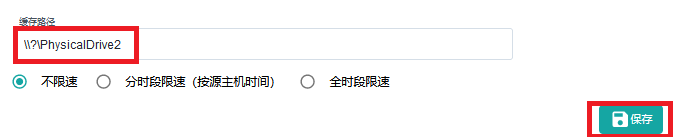
LiveCD
登录目标机终端或控制台,运行以下命令
lsblk假定
sdd为新增磁盘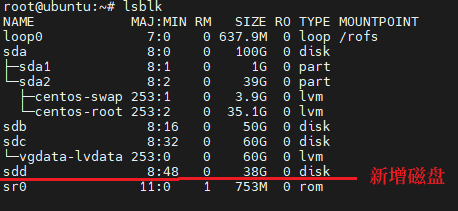
回到Easync控制中心,选择计划->目标主机,在缓存路径字段输入如下,点击保存按钮。
/dev/sdd
切换完成后,缓存盘不再需要,可以卸载删除。
如何在RamOS目标机上增加数据缓存(指定缓存目录)?
登录目标机所在的云平台控制台,给目标机增加一块虚拟磁盘。如果目标机是物理机,则需要增加一块物理磁盘。
数据缓存盘大小取决于源生产端数据变化率、全量同步所需时间(取决于全量数据量、磁盘性能、带宽等)。可以大致建议为源主机全量数据的10%~30%。
这块磁盘将专门用作数据缓存,迁移完成后可以删除。
登录目标机控制台。请按平台执行步骤
WinPE
点击工具->运行,输入cmd,回车
在命令行窗口输入以下命令
diskpartlist disk列出磁盘。假定最后一块磁盘为新增磁盘,磁盘序号是 4。
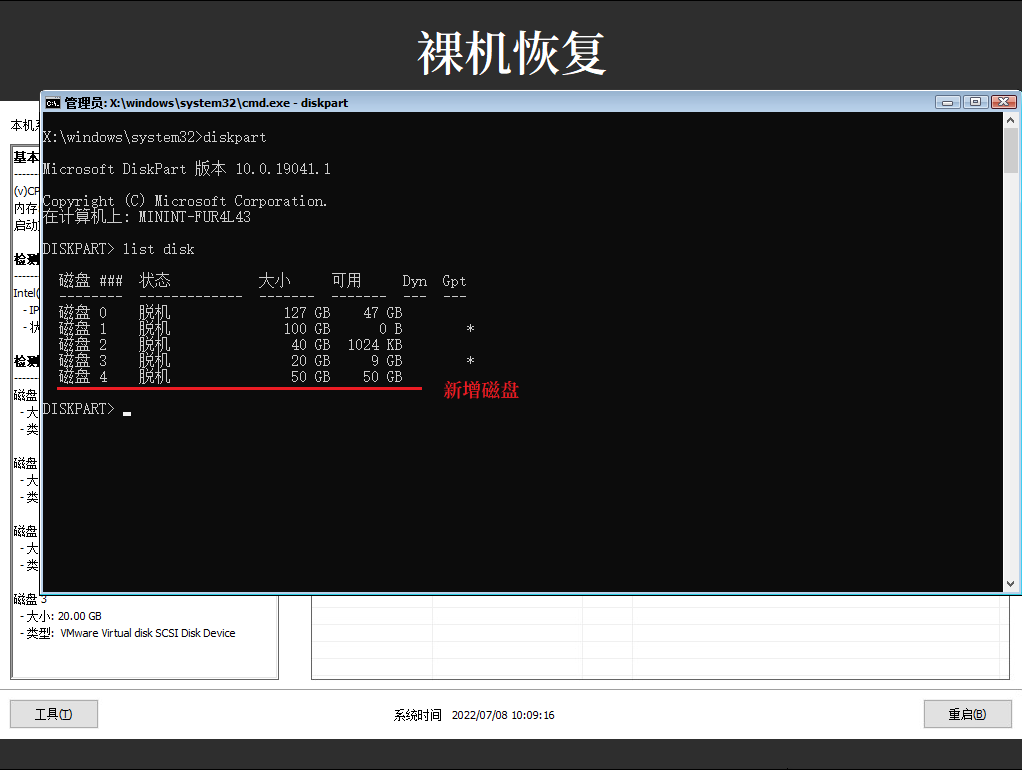
sel disk 4online diskcleanattributes disk clear readonlycreate part primarysel part 1assign letter=sformat fs=ntfs quicklist vol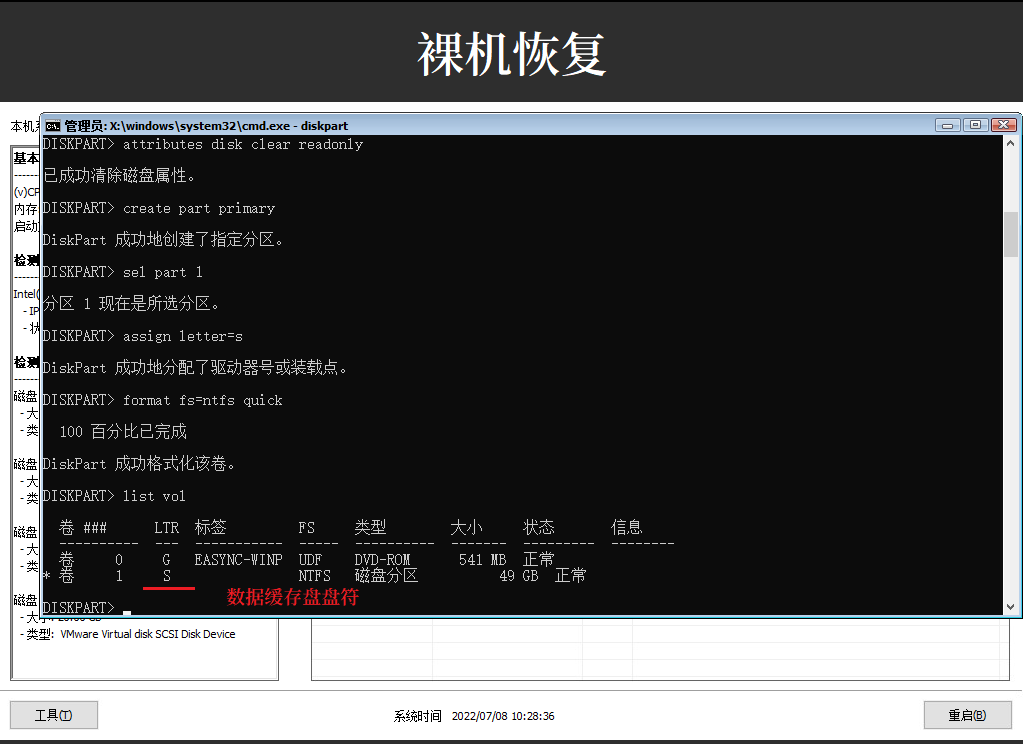
LiveCD
登录目标机终端或控制台
运行以下命令
lsblk假定sdd为新增磁盘
mkfs.xfs -f /dev/sddmkdir /esspoolmount -t xfs /dev/sdd /esspooldf -h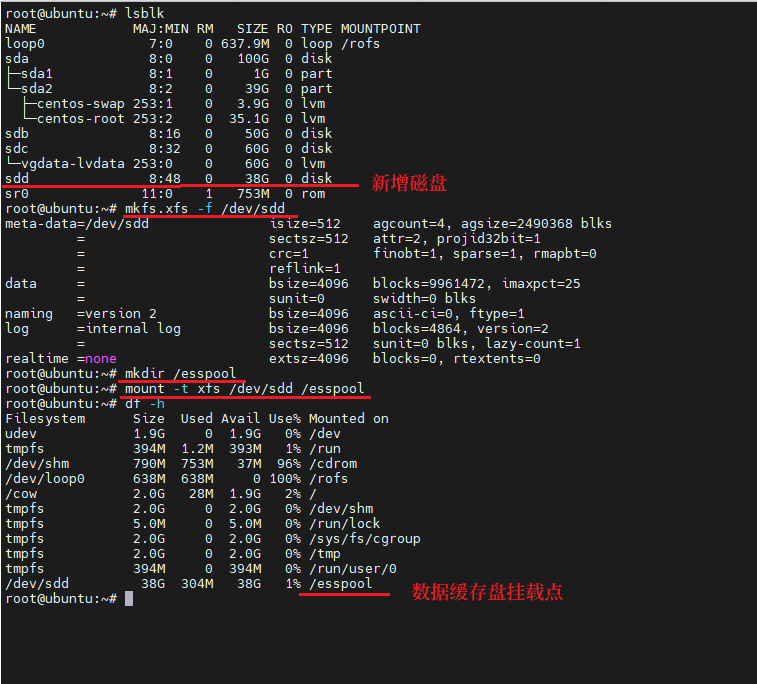
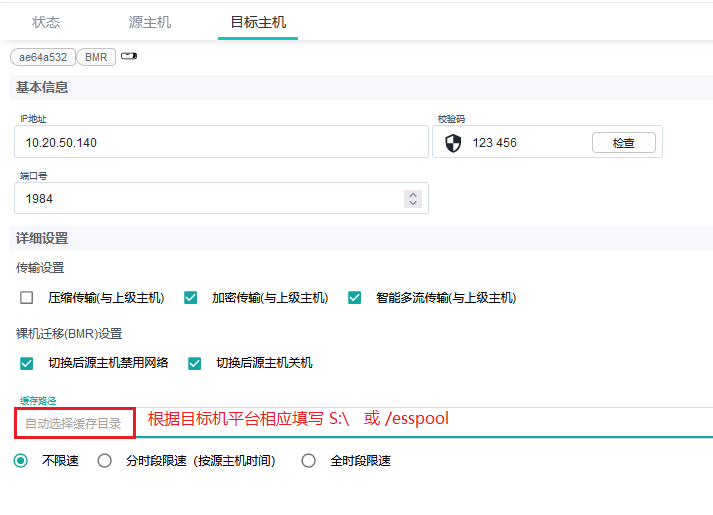
在Easync控制中心界面,选择计划->目标主机,根据目标机平台不同,相应设置缓存目录
切换完成后,缓存盘不再需要,可以卸载删除。
事件和日志
配置事件邮件通知
请在顶部工具->邮件通知里进行smtp设置。
smtp邮件通知支持SSL/TLS/STARTTLS加密设置。请参考邮件服务器供应商帮助文档设置相应属性。
注意:163邮箱对于第三方邮件客户端登录,要求输入授权码,而不是账户密码。请在163邮箱帮助页面生成授权码,在本页面账户密码框输入。
如何将控制中心日志输出到syslog服务器
关于syslog服务器的配置请参考相应文档。此处假定syslog服务器已经配置正确并且可用。
需要syslog服务器IP地址、端口号、协议。
控制中心安装后,在控制中心主机上运行如下命令:
xxxxxxxxxxecho [syslog-server-ip] > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_HOSTecho [port] > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_PORTecho [tcp|udp] > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_PROTOesccmgr restart
例如
xxxxxxxxxxecho 10.20.50.130 > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_HOSTecho 514 > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_PORTecho udp > /opt/cloudock/easync/cc/data/EASYNC_SYSLOG_PROTOesccmgr restart
后续控制中心日志、包括源主机、目标机发送到控制中心的事件将被发送到syslog服务器中。
通用模式迁移获取源和目标端迁移过程完整日志
对于通用模式迁移,在切换前,取消选择目标主机的“切换后目标机自动重启”选项,保存,然后再点切换
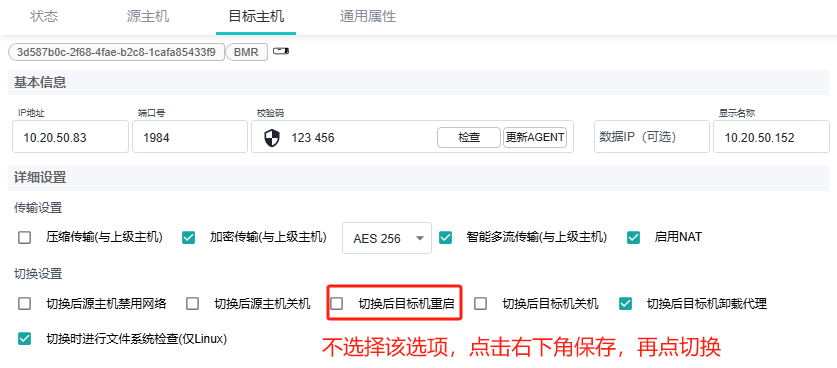
等待切换完成,此时目标机将不会自动重启,仍然运行在ramos。点击“下载代理日志”,日志将包含源、目标两端日志。
此时可以分析日志。
排错时需要收集的信息
截图
一般包含如下截图,更多截图更有帮助排错。
计划页面
建议全屏截图。包括左侧计划展开树状结构,右侧计划运行状态、数据同步状态(如果是正在运行的计划),右下方尽可能多的最新事件。
如果计划名等含有敏感信息,可以打马赛克。
问题页面/窗口
例如vm启动失败,vm启动后IP错误、硬盘不显示、卷标错误等,相应截图。
日志
代理日志
选择计划,右上角点击下载代理日志。
正常情况下,下载的zip文件里会包含源主机、VA两个主机的压缩包。
如果只包含一个主机的zip,则表示另一台主机agent无法连接。此时可以手动到该主机运行如下命令,将生成日志压缩包。
Windows:
C:\Program Files\Cloudock\Easync\agent\common\getlogs.batLinux:
/opt/cloudock/easync/common/getlogs.sh也可以将该主机的代理服务重启(
Windows:EasyncAgentService;Linux:/etc/init.d/easync-agent restart),等待几十秒,再次尝试【下载代理日志】。vm_helper日志
对于切换后的Windows目标机,如果登录后发现IP地址没有设置、设置错误,或数据卷不显示、没有盘符,请收集下方日志:
C:\Program Files\Cloudock\Easync\agent\data\logs\es_vm_helper.log如果代理已经卸载,上述文件已被删除,则检查此位置:
C:\Temp\logs\es_vm_helper.logLinux不需要这个日志。
代理运行异常时获取更多诊断信息
当代理没有运行时,上述方法无法获得日志,请登录主机,手动运行命令:
Windows: C:\Program Files\Cloudock\Easync\agent\common\getlogs.bat
Linux: /opt/cloudock/easync/common/getlogs.sh